State-of-the-art speech synthesis models are based on parametric neural networks. Text-to-speech (TTS) synthesis is typically done in two steps.
- In the first step, a synthesis network transforms the text into time-aligned features, such as a spectrogram, or fundamental frequencies, which are the frequency at which vocal cords vibrate in voiced sounds.
- In the second step, a vocoder network converts the time-aligned features into audio waveforms.

Preparing the input text for synthesis requires text analysis, such as converting text into words and sentences, identifying and expanding abbreviations, and recognizing and analyzing expressions. Expressions include dates, amounts of money, and airport codes.
The output from text analysis is passed into linguistic analysis for refining pronunciations, calculating the duration of words, deciphering the prosodic structure of utterance, and understanding grammatical information.
Output from linguistic analysis is then fed to a speech synthesis neural network model, such as Tacotron2, which converts the text to mel spectrograms and then to a neural vocoder model like Wave Glow to generate the natural sounding speech.
Popular deep learning models for TTS include Wavenet, Tacotron 2, and WaveGlow.
In 2006, Google WaveNet introduced deep learning techniques with a new approach that directly modeled the raw waveform of the audio signal one sample at a time. Its model is probabilistic and autoregressive, with the predictive distribution for each audio sample conditioned on all previous ones. WaveNet is a fully convolutional neural network with the convolutional layers having various dilation factors that allow its receptive field to grow exponentially with depth. Input sequences are waveforms recorded from human speakers.
 deepmind)
deepmind)
Tacotron 2 is a neural network architecture for speech synthesis directly from text using a recurrent sequence-to-sequence model with attention. The encoder (blue blocks in the figure below) transforms the whole text into a fixed-size hidden feature representation. This feature representation is then consumed by the autoregressive decoder (orange blocks) that produces one spectrogram frame at a time. In the NVIDIA Tacotron 2 and WaveGlow for PyTorch model, the autoregressive WaveNet (green block) is replaced by the flow-based generative WaveGlow.

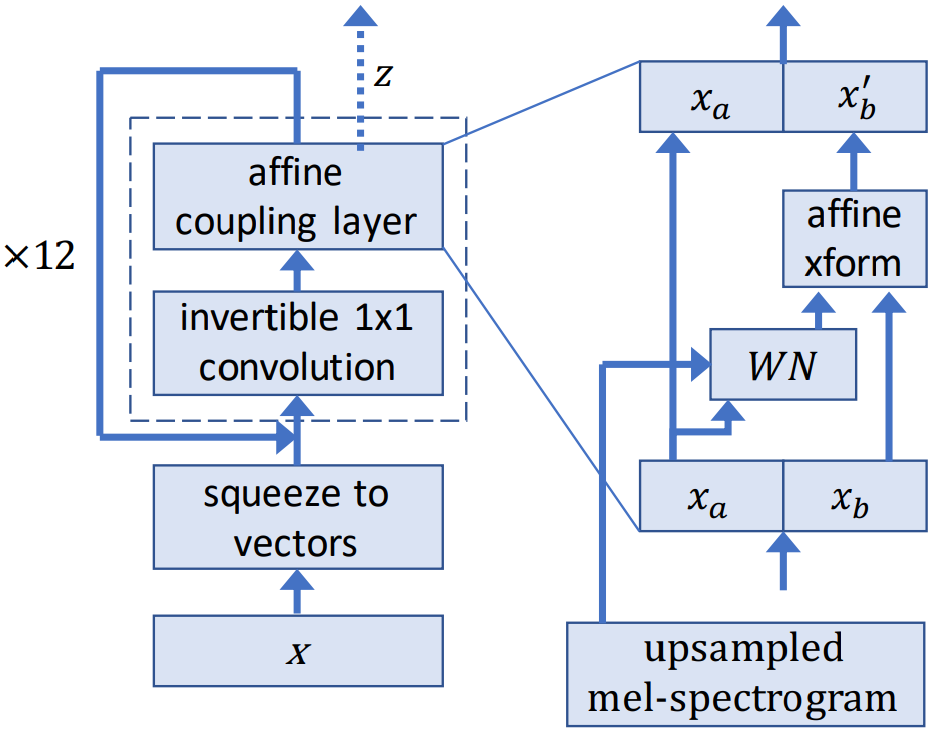
WaveGlow is a flow-based model that consumes the mel spectrograms to generate speech.
During training, the model learns to transform the dataset distribution into spherical Gaussian distribution through a series of flows. One step of a flow consists of an invertible convolution, followed by a modified WaveNet architecture that serves as an affine coupling layer. During inference, the network is inverted and audio samples are generated from the Gaussian distribution.