A Deeper Look At VRAM On GeForce RTX 40 Series Graphics Cards
We receive a lot of questions about graphics memory, also known as the frame buffer, video memory, or “VRAM”, and so with the unveiling of our new GeForce RTX 4060 Family of graphics cards we wanted to share some insights, so gamers can make the best buying decisions for their gaming needs.
What Is VRAM?
VRAM is high speed memory located on your graphics card. It’s one component of a larger memory subsystem that helps make sure your GPU has access to the data it needs to smoothly process and display images.
In this article, we’ll describe memory subsystem innovations in our latest generation Ada Lovelace GPU architecture, as well as how the speed and size of GPU cache and VRAM impacts performance and the gameplay experience.
GeForce RTX 40 Series Graphics Cards Memory Subsystem: Improving Performance & Efficiency
Modern games are graphical showcases, and their install sizes can now exceed 100GB. Accessing this massive amount of data happens at different speeds, determined by the specifications of the GPU, and to some extent your system’s other components.
On GeForce RTX 40 Series graphics cards, new innovations accelerate the process for smooth gaming and faster frame rates, helping you avoid texture stream-in or other hiccups.
The Importance Of Cache
GPUs include high-speed memory caches that are close to the GPU’s processing cores, which store data that is likely to be needed. If the GPU can recall the data from the caches, rather than requesting it from the VRAM (further away) or system RAM (even further away), the data will be accessed and processed faster, increasing performance and gameplay fluidity, and reducing power consumption.
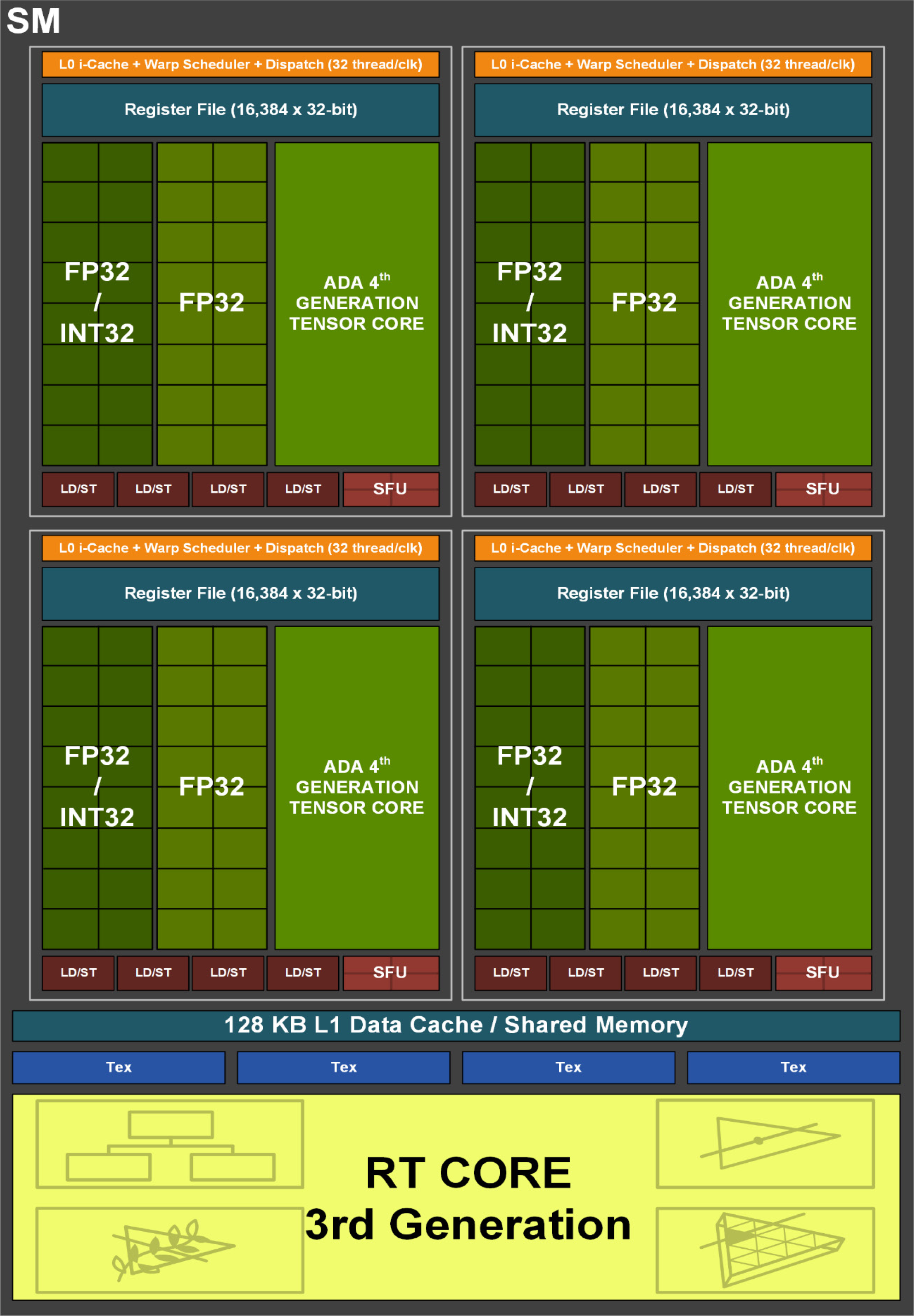
GeForce GPUs feature a Level 1 (L1) cache (the closest and fastest cache) in each Streaming Multiprocessor (SM), up to twelve of which can be found in each GeForce RTX 40 Series Graphics Processing Cluster (GPC). This is followed by a fast, larger, shared Level 2 (L2) cache that can be accessed quickly with minimal latency.
Accessing each cache level incurs a latency hit, with the tradeoff being greater capacity. When designing our GeForce RTX 40 Series GPUs, we found a singular, large L2 cache to be faster and more efficient than other alternatives, such as those featuring a small L2 cache, and a large, slower to access L3 cache.
Prior generation GeForce GPUs had much smaller L2 Caches, resulting in lower performance and efficiency compared to today’s GeForce RTX 40 Series GPUs.

During use, the GPU first searches for data in the L1 data cache within the SM, and if the data is found in L1 there’s no need to access the L2 data cache. If data is not found in L1, it’s called a “cache miss”, and the search continues into the L2 cache. If data is found in L2, that’s called an L2 “cache hit” (see the “H” indicators in the above diagram), and data is provided to the L1 and then to the processing cores.
If data is not found in the L2 cache, an L2 “cache miss”, the GPU now tries to obtain the data from the VRAM. You can see a number of L2 cache misses in the above diagram that depicts our prior architecture memory subsystem, which causes a number of VRAM accesses.
If the data’s missing from the VRAM, the GPU requests it from your system’s memory. If the data is not in system memory, it can typically be loaded into system memory from a storage device like an SSD or hard drive. The data is then copied into VRAM, L2, L1, and ultimately fed to the processing cores. Note that different hardware -and software- based strategies exist to keep the most useful, and most reused data present in caches.
Each additional data read or write operation through the memory hierarchy slows performance and uses more power, so by increasing our cache hit rate we increase frame rates and efficiency.

Compared to prior generation GPUs with a 128-bit memory interface, the memory subsystem of the new NVIDIA Ada Lovelace architecture increases the size of the L2 cache by 16X, greatly increasing the cache hit rate. In the examples above, representing 128-bit GPUs from Ada and prior generation architectures, the hit rate is much higher with Ada. In addition, the L2 cache bandwidth in Ada GPUs has been significantly increased versus prior GPUs. This allows more data to be transferred between the cores and the L2 cache as quickly as possible.
Shown in the diagram below, NVIDIA engineers tested the RTX 4060 Ti with its 32 MB L2 cache against a special test version of RTX 4060 Ti using only a 2 MB L2, which represents the L2 cache size of previous generation 128-bit GPUs (where 512 KB of L2 cache was tied to each 32-bit memory controller).
In testing with a variety of games and synthetic benchmarks, the 32 MB L2 cache reduced memory bus traffic by just over 50% on average compared to the performance of a 2 MB L2 cache. See the reduced VRAM accesses in the Ada Memory Subsystem diagram above.
This 50% traffic reduction allows the GPU to use its memory bandwidth 2X more efficiently. As a result, in this scenario, isolating for memory performance, an Ada GPU with 288 GB/sec of peak memory bandwidth would perform similarly to an Ampere GPU with 554 GB/sec of peak memory bandwidth. Across an array of games and synthetic tests, the greatly increased hit rates improve frame rates by up to 34%.

Memory Bus Width Is One Aspect Of A Memory Subsystem
Historically, memory bus width has been used as an important metric for determining the speed and performance class of a new GPU. However, the bus width by itself is not a sufficient indicator of memory subsystem performance. Instead, it’s helpful to understand the broader memory subsystem design and its overall impact on gaming performance.
Due to the advances in the Ada architecture, including new RT and Tensor Cores, higher clock speeds, the new OFA Engine, and Ada’s DLSS 3 capabilities, the GeForce RTX 4060 Ti is faster than the previous-generations, 256-bit GeForce RTX 3060 Ti and RTX 2060 SUPER graphics cards, all while using less power.
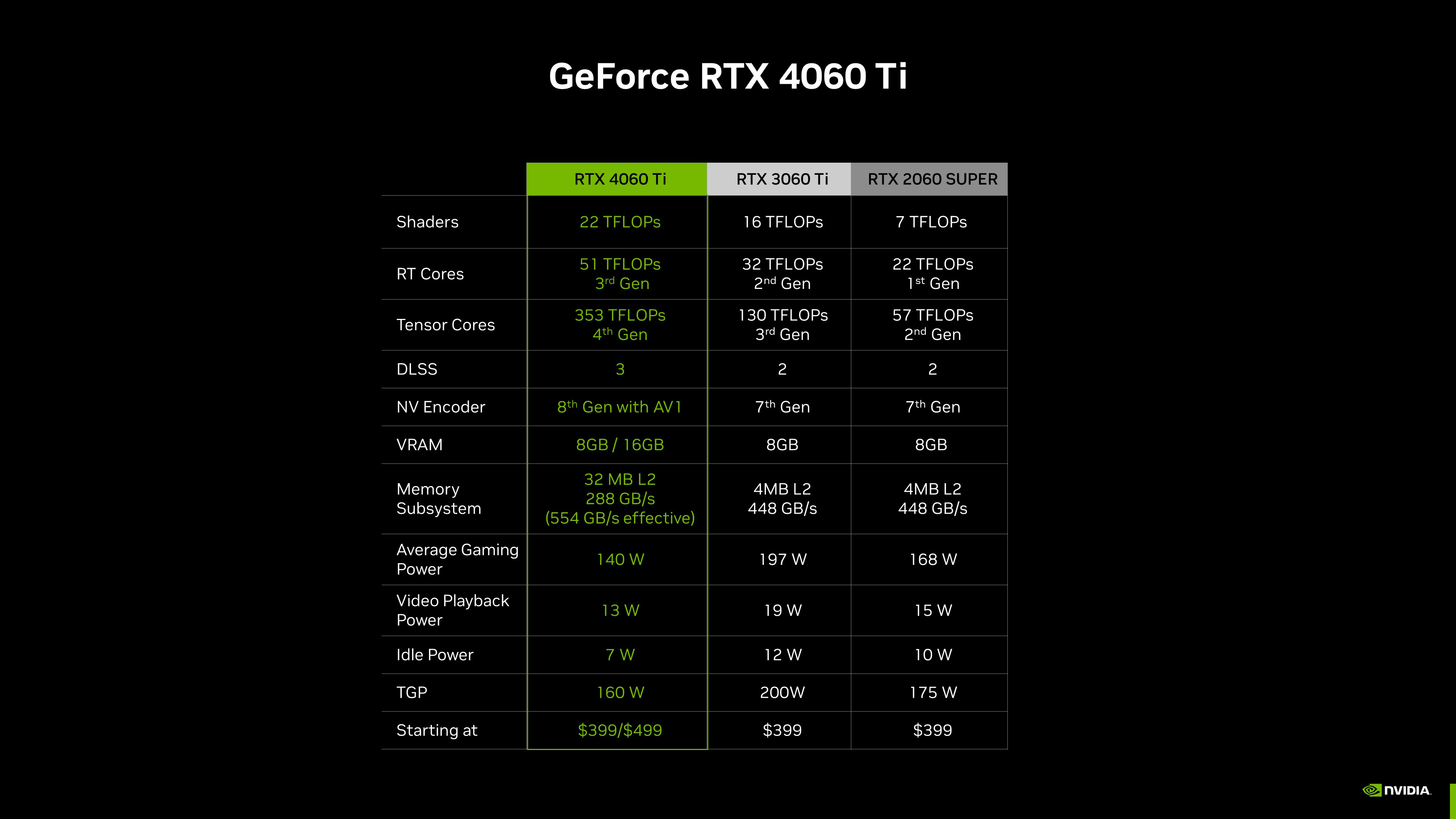
Altogether, the tech specs deliver a great 60-class GPU with high performance for 1080p gamers, who account for the majority of Steam users.

The Amount of VRAM Is Dependent On GPU Architecture
Gamers often wonder why a graphics card has a certain amount of VRAM.
Current-generation GDDR6X and GDDR6 memory is supplied in densities of 8Gb (1GB of data) and 16Gb (2GB of data) per chip. Each memory chip can use either two separate 16-bit channels to connect to a single 32-bit memory controller, or two 8-bit channels, so two memory chips can connect to a single 32-bit memory controller. This allows a 128-bit GPU to support either 4 memory chips or 8 memory chips.
Higher capacity chips cost more to make, so a balance is required to optimize prices.
On our new 128-bit memory bus GeForce RTX 4060 Ti GPUs, the 8GB model uses four 16Gb GDDR6 memory chips, and the 16GB model uses eight 16Gb chips. Mixing densities isn’t possible, preventing the creation of a 12GB model, for example. That’s also why the GeForce RTX 4060 Ti has an option with more memory (16GB) than the GeForce RTX 4070 Ti and 4070, which have 192-bit memory interfaces and therefore 12GB of VRAM.
Our 60-class GPUs have been carefully crafted to deliver the optimum combination of performance, price, and power efficiency, which is why we chose a 128-bit memory interface.
In short, higher capacity GPUs of the same bus width always have double the memory.
Do On Screen Display (OSD) Tools Report VRAM Usage Accurately?
Gamers often cite the “VRAM usage” metric in On Screen Display performance measurement tools. But this number isn’t entirely accurate, as all games and game engines work differently.
In the majority of cases, a game will allocate VRAM for itself, saying to your system, ‘I want it in case I need it’. But just because it’s holding the VRAM, doesn’t mean it actually needs all of it. In fact, games will often request more memory if it’s available.
Due to the way memory works, it’s impossible to know precisely what’s being actively used unless you’re the game’s developer with access to development tools. Some games offer a guide in the options menu, but even that isn’t always accurate.
The amount of VRAM that is actually needed will vary in real time depending on the scene and what the player is seeing.
Furthermore, the behavior of games can vary when VRAM is genuinely used to its max. In some, memory is purged causing a noticeable performance hitch while the current scene is reloaded into memory. In others, only select data will be loaded and unloaded, with no visible impact. And in some cases, new assets may load in slower as they’re now being brought in from system RAM.
For gamers, playing is the only way to truly ascertain a game’s behavior. In addition, gamers can look at "1% low” framerate measurements, which can help analyze the actual gaming experience. The 1% Low metric —found in the performance overlay and logs of the free NVIDIA FrameView app, as well as other popular measurement tools— measures the average of the slowest 1% of frames over a certain time period.
Automate Setting Selection With GeForce Experience & Download The Latest Patches
Recently, some new games have released patches to better manage memory usage, without hampering the visual quality. Make sure to get the latest patches for new launches, as they commonly fix bugs and optimize performance shortly after launch.
Additionally, GeForce Experience supports most new games, offering optimized settings for each supported GeForce GPU and VRAM configuration, giving gamers the best possible experience by balancing performance and image quality.
If you’re unfamiliar with game option lingo and just want to enjoy your games from the second you load them, GeForce Experience can automatically tune game settings for a great experience each time.
NVIDIA Technologies Can Help Developers Reduce VRAM Usage
Games are richer and more detailed than ever before, necessitating those 100GB+ installs. To help developers optimize memory usage, NVIDIA has several free developer tools and SDKs, including:
- NVIDIA RTX Memory Utility (RTXMU): Ray tracing requires additional VRAM. RTXMU can reduce this usage by up to 50%
- NVIDIA Micro-Mesh SDK: Reduces the memory usage of complex geometry while also increasing performance
- NVIDIA Texture Tools Exporter: Creates highly compressed texture files to reduce memory usage and the file size of games
These are just a few of the tools and technologies that NVIDIA freely provides to help developers optimize their games for all GPUs, platforms, and memory configurations.
Some Applications Can Use More VRAM
Beyond gaming, GeForce RTX graphics cards are used around the world for 3D animation, video editing, motion graphics, photography, graphic design, architectural visualization, STEM, broadcasting, and AI. Some of the applications used in these industries may benefit from additional VRAM. For example, when editing 4K or 8K timelines in Premiere, or crafting a massive architectural scene in D5 Render.
On the gaming side, high resolutions also generally require an increase in VRAM. Occasionally, a game may launch with an optional extra large texture pack and allocate more VRAM. And there are a handful of games which run best at the “High” preset on the 4060 Ti (8GB), and maxed-out "Ultra" settings on the 4060 Ti (16GB). In most games, both versions of the GeForce RTX 4060 Ti (8GB and 16GB) can play at max settings and will deliver the same performance.
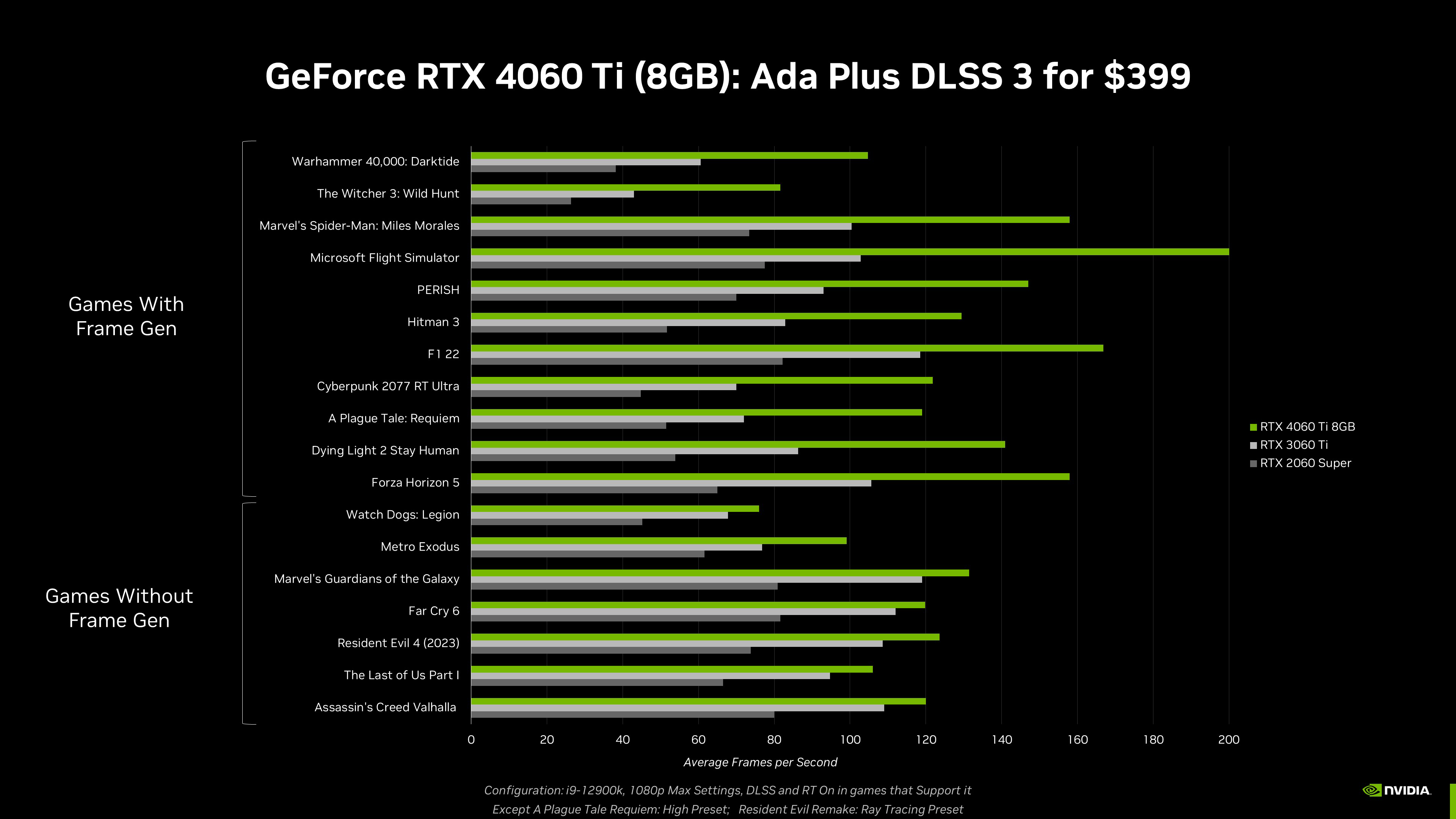
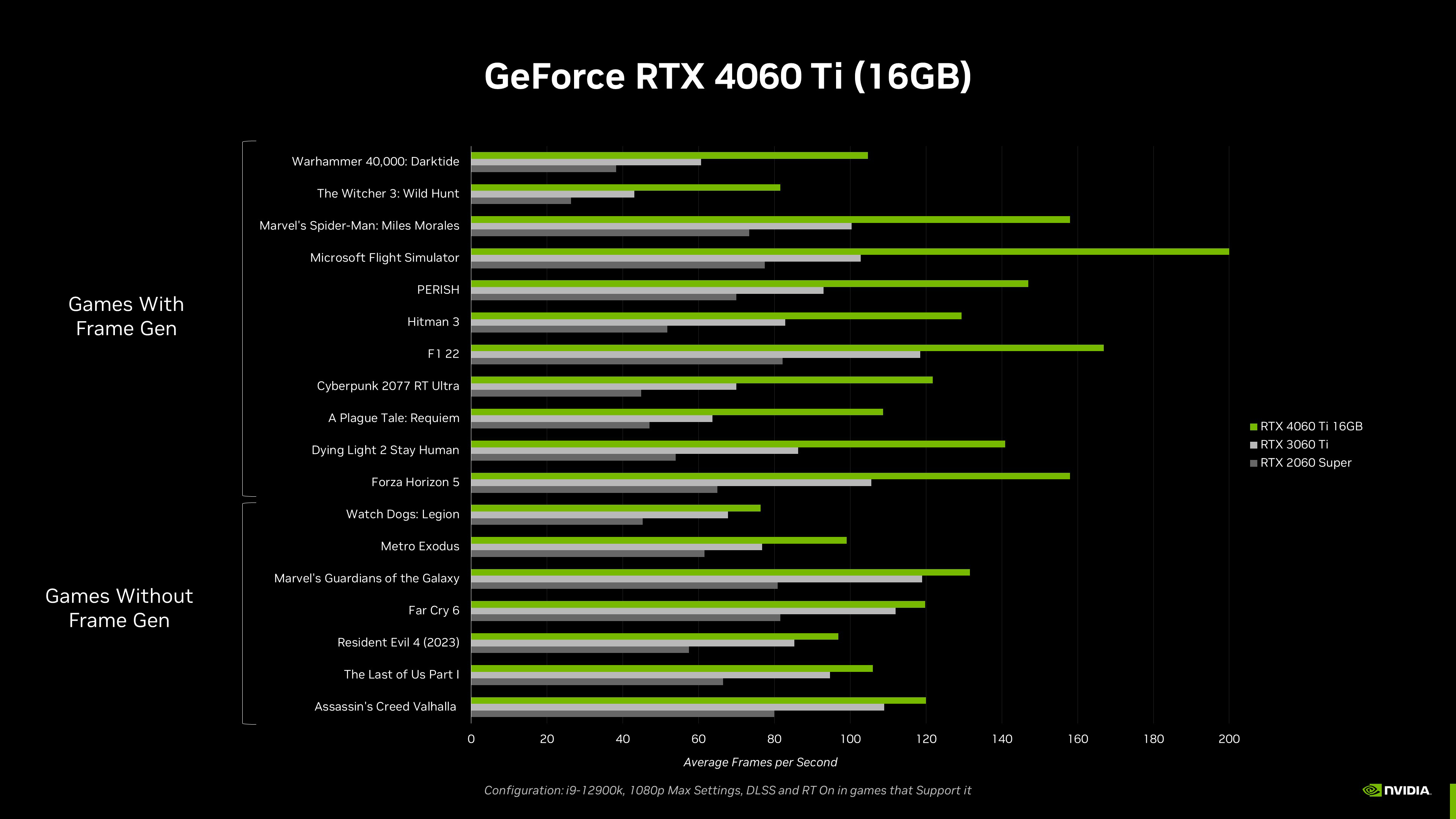
The benefit of the PC platform is its openness, configurability and upgradability, which is why we’re offering the two memory configurations for the GeForce RTX 4060 Ti; if you want that extra VRAM, it will be available in July.
A GPU For Every Gamer
Following the launch of the GeForce RTX 4060 Family, there’ll be optimized graphics cards for each of the three major game resolutions. However you play, all GeForce RTX 40 Series GPUs will deliver a best-in-class experience, with leading power efficiency, supported by a massive range of game-enhancing technologies, including NVIDIA DLSS 3, NVIDIA Reflex, NVIDIA G-SYNC, NVIDIA Broadcast, and RTX Remix.

For the latest news about all the new games and apps that leverage the full capabilities of GeForce RTX graphics cards, stay tuned to GeForce.com.