Dask is an open source flexible library for parallel and distributed computing in Python.
Dask
How Does Dask Work?
Dask is an open-source library designed to provide parallelism to the existing Python stack. It provides integrations with Python libraries like NumPy Arrays, Pandas DataFrames, and scikit-learn to enable parallel execution across multiple cores, processors, and computers without having to learn new libraries or languages.
Dask is composed of two parts:
- A collections API for parallel lists, arrays, and DataFrames for natively scaling Numpy, NumPy, Pandas, and scikit-learn to run in larger-than-memory or distributed environments. Dask collections are parallel collections from the underlying library (eg. a Dask array consists of Numpy arrays) and run on top of the task scheduler.
- A task scheduler for building task graphs and coordinating, scheduling, and monitoring tasks optimized for interactive workloads across CPU cores and machines.

Dask’s three parallel collections—called DataFrames, Bags, and Arrays—can each automatically use data partitioned between RAM and disk as well, distributed across multiple nodes in a cluster, depending on resource availability. For problems that are parallelizable but don’t fit well in high-level abstractions like Dask Arrays or DataFrames, there’s a “delayed” function that uses Python decorators to modify functions so that they operate lazily. That means that execution is delayed, and the function and its arguments placed into a task graph.
Dask’s task scheduler can scale to thousand-node clusters and its algorithms have been tested on some of the world’s largest supercomputers. Its task scheduling interface can also be customized for specific jobs. Dask delivers the low-overhead, low-latency, and minimal serialization necessary for speed.
In a distributed scenario, one scheduler coordinates many workers and moves computation to the correct worker maintaining a continuous, non-blocking conversation. Several users may share the same system. This approach works with the Hadoop HDFS file system, as well as cloud object stores such as Amazon’s S3 storage.
The single-machine scheduler is optimized for larger-than-memory use and divides tasks across multiple threads and processors. It uses a low-overhead approach that consumes roughly 50 microseconds per task.
Why Dask?
Python‘s user-friendly, high-level programming language and python libraries like NumPy, Pandas, and scikit-learn have seen significant adoption by data scientists.
Developed before big data use cases became so prevalent, these libraries didn’t have a strong solution for parallelism. Python was the go-to choice for single-core computing, but users were forced to find other solutions for multi-core or multi-machine parallelism. This caused frustration and a break in user experience.
This growing need to scale workloads in Python has led to the natural growth of Dask over the last five years. Dask is an easily installed, rapidly provisioned way to speed up data analysis in Python that doesn’t require developers to upgrade their hardware infrastructure or switch to another programming language. The syntax used to launch Dask jobs is the same as that used for other Python operations, so it can be integrated with little code rework.

Also popular with web developers, Python has a robust networking stack that Dask leverages to build a flexible, performant distributed computing system capable of scaling a wide variety of workloads. Dask’s flexibility helps it to stand out against other big data solutions like Hadoop or Apache Spark, and its support of native code makes it particularly easy to work with for Python users and C/C++/CUDA developers.
Dask has been quickly adopted by the Python developer community and has grown with the popularity of Numpy and Pandas, which provide valuable extensions to Python to address special analytics and mathematical calculations.
It also scales much better than Pandas and works particularly well on tasks that are easily parallelized, such as sorting data across thousands of spreadsheets. The accelerator can load hundreds of Pandas DataFrames into memory and coordinate them with a single abstraction.
Today, Dask is managed by a community of developers that spans dozens of institutions and PyData projects such as Pandas, Jupyter, and Scikit-Learn. Dask’s integration with these popular tools has led to rapidly rising adoption, with about 20% adoption among developers who need Pythonic big data tools.

Figure 1: Big data tools used by Python developers (>100%). Sourced from JetBrains.
Why Dask is Better With GPUs
Architecturally, the CPU is composed of just a few cores with lots of cache memory that can handle a few software threads at a time. In contrast, a GPU is composed of hundreds of cores that can handle thousands of threads simultaneously.
GPUs deliver the once-esoteric technology of parallel computing.
Dask + NVIDIA: Driving Accessible Accelerated Analytics
NVIDIA understands the power that GPUs offer to data analytics. That’s why it has worked hard to empower practitioners of data science, machine learning, and artificial intelligence to get the most out of their data. Seeing the power and accessibility of Dask, NVIDIA started using it on the RAPIDS™ project with the goal of horizontally scaling accelerated data analytics workloads to multiple GPUs and GPU-based systems.

Due to the accessible Python interface and versatility beyond data science, Dask grew to other projects throughout NVIDIA, becoming a natural choice in new applications ranging from parsing JSON to managing end-to-end deep learning workflows. Here are a few of NVIDIA’s many ongoing projects and collaborations using Dask:
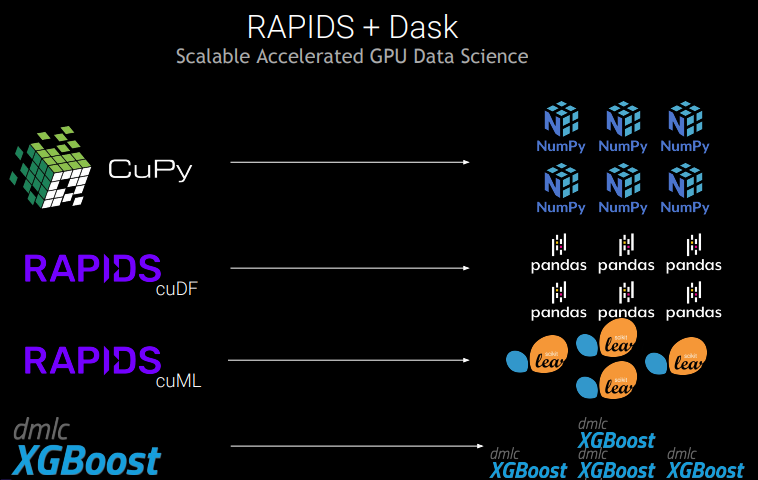
RAPIDS
RAPIDS is a suite of open-source software libraries and APIs for executing data science pipelines entirely on GPUs, often reducing training times from days to minutes. Built on built on CUDA, RAPIDS unites years of development in graphics, machine learning, high-performance computing (HPC), and more.

While CUDA is incredibly powerful, most data analytics practitioners prefer experimenting, building, and training models with a Python toolset, like the aforementioned NumPy, Pandas, and Scikit-learn. Dask is a critical component of the RAPIDS ecosystem, making it even easier for data practitioners to take advantage of accelerated computing through a comfortable Python-based user experience.
NVTabular
NVTabular is a feature engineering and preprocessing library designed to quickly and easily manipulate terabytes of tabular datasets. Built on the Dask-cuDF library, it provides a high-level abstraction layer that simplifies the creation of high-performance ETL operations at massive scale. NVTabular is able to scale to thousands of GPUs by leveraging RAPIDS and Dask, eliminating the bottleneck of waiting for ETL processes to finish.
BlazingSQL
BlazingSQL is an incredibly fast distributed SQL engine on GPUs also built upon Dask-cuDF. It enables data scientists to easily connect large-scale data lakes to GPU-accelerated analytics. With a few lines of code, practitioners can directly query raw file formats such as CSV and Apache Parquet inside Data Lakes like HDFS and AWS S3, and directly pipe the results into GPU memory.
BlazingDB Inc, the company behind BlazingSQL, is a core contributor to RAPIDS and collaborates heavily with NVIDIA.
cuStreamz
Internally NVIDIA uses Dask to fuel parts of its products and business operations. Using Streamz, Dask, and RAPIDS, they’ve built cuStreamz, an accelerated streaming data platform using 100% native Python. With cuStreamz, they’re able to conduct real-time analytics for some of the most demanding applications like GeForce NOW™, NVIDIA GPU Cloud, and NVIDIA DRIVE Sim™. While it’s a young project, NVIDIA has already seen impressive reductions to the total cost of ownership over other streaming data platforms using the Dask-enabled cuStreamz.
Use Cases for Dask
Dask's ability to process hundreds of terabytes of data efficiently makes it a powerful tool to add parallelism to machine learning (ML) processing. It enables faster execution of large, multi-dimensional datasets analysis, and accelerates and scales data science pipelines or workflows. As such, it can be used in a wide variety of use cases in HPC, financial services, cyber security, and retail. For example, Dask works with Numpy workflows to enable multi-dimensional data analysis in earth science, satellite imagery, genomics, biomedical applications, and machine learning algorithms.
Using Pandas DataFrames, Dask can enable applications in time series analysis, business intelligence, and data preparation. Dask-ML, which is a library for distributed and parallel machine learning, can be used with Scikit-Learn and XGBoost to create scalable training and prediction on large models and datasets. Developers can use standard Dask workflows to prepare and set up data, then hand the data over to XGBoost or Tensorflow.
Dask + RAPIDS: Enabling Innovation in the Enterprise
Many companies are adopting both Dask and RAPIDS to scale some of their most important operations. Some of NVIDIA’s biggest partners, leaders in their industries, are using them to power their data analytics. Here are some recent exciting examples:
Capital One
On a mission to “change banking for good,” Capital One has invested heavily in large-scale data analytics to provide better products and services to its customers and improve operational efficiencies across their enterprise. With a large community of Python-friendly data scientists, Capital One uses Dask and RAPIDS to scale and accelerate traditionally hard-to-parallelize Python workloads and significantly lessen the learning curve for big data analytics.
National Energy Research Scientific Computing Center
Devoted to providing computational resources and expertise for basic scientific research, NERSC is a world leader in accelerating scientific discovery through computation. Part of that mission is making supercomputing accessible to researchers to fuel scientific exploration. With Dask and RAPIDS, the incredible power of their latest supercomputer “Perlmutter” becomes easily accessible by researchers and scientists with limited background in supercomputing. By leveraging Dask to create a familiar interface, they put the power of supercomputing into the hands of scientists driving potential breakthroughs across fields.
Oak Ridge National Laboratory
In the midst of a global pandemic, Oak Ridge National Laboratory is pushing boundaries of innovation by building a “virtual lab” for drug discovery in the fight against COVID-19. Using Dask, RAPIDS, BlazingSQL, and NVIDIA GPUs, researchers are able to use the power of the Summit supercomputer from their laptops to screen small-molecule compounds abilities to bind with the SARS-CoV-2 main protease. With such a flexible toolset, engineers were able to get this custom workflow up and running in less than two weeks and see sub-second query results
Walmart Labs
A giant in the retail space, Walmart uses massive datasets to better serve their customers, predict product needs, and improve internal efficiencies. Relying on large-scale data analytics to accomplish these goals, Walmart Labs has turned to Dask, XGBoost, and RAPIDS to reduce training times by 100X enabling fast model iteration and accuracy improvements to further their business. With Dask, they open up the power of NVIDIA GPUs to data scientists to solve their hardest problems.
Dask in the Enterprise: A Growing Market
With its growing success in large institutions, more companies are filling the need for Dask products and services in the enterprise. Here are some companies that are addressing enterprise Dask needs, signaling the beginnings of a maturing market:
Anaconda
Like a large portion of the SciPy ecosystem, Dask began at Anaconda Inc, where it gained traction and matured into a larger open-source community. As the community grew and enterprises began adopting Dask, Anaconda began providing consulting services, training, and open-source support to ease enterprise usage. A major proponent of open-source software, Anaconda also employs many Dask maintainers, providing a deep understanding of the software to enterprise customers.
Coiled
Founded by Dask maintainers—like Dask project lead and former NVIDIAN Matthew Rocklin—Coiled provides a managed solution around Dask to make it easy in both cloud and enterprise environments, as well as enterprise support to help optimize Python analytics within institutions. Their publicly hosted managed deployment product provides a robust yet intuitive way to use both Dask and RAPIDS today.
Quansight
Dedicated to helping enterprises create value out of their data, Quansight provides a variety of services to propel data analytics across industries. Similar to Anaconda, Quansight provides consulting services and training to enterprises using Dask. Engrained with the PyData and NumFOCUS ecosystems, Quansight also provides support for enterprises that need enhancements or bug fixes in open source software.
Why Dask Matters to Data ScienceTeams
It’s all about acceleration and efficiency. Developers working on interactive algorithms want rapid execution so they can tinker with inputs and variables. Desktop and laptop computers with limited memory can be frustratingly underpowered when running large data sets. Dask has functionality out of the box that makes processing more efficient even on a single CPU. When applied to a cluster, executing an operation across multiple CPUs and GPUs can often be done with a single command that cuts processing time by 90%. Dask can enable the very large training data sets that are typical of machine learning to run in environments that would otherwise be unable to support them.
With a low-code structure, low-overhead execution model, and easy integration into Python, Pandas, and Numpy workflows, Dask is fast becoming part of every Python developer’s toolkit.
Next Steps
- Learn more about RAPIDS + DASK here
- Find out more about: