In Chapter 1, we explored how Spark DataFrames execute on a cluster. In this chapter, we’ll provide you with an overview of DataFrames and Spark SQL programming, starting with the advantages.
Spark SQL and DataFrame Programming
DataFrames and Spark SQL Advantages
The Spark SQL and the DataFrame APIs provide ease of use, space efficiency, and performance gains with Spark SQL's optimized execution engine.
Optimized Memory Usage
Spark SQL caches DataFrames (when you call dataFrame.cache) using an in-memory columnar format which is optimized to: scan only required columns, automatically tune compression, minimize memory usage and minimize JVM Garbage Collection.

Spark SQL Vectorized Parquet and ORC readers decompress and decode in column batches, which is roughly nine times faster for reading.
Query Optimization
Spark SQL’s Catalyst Optimizer handles logical optimization and physical planning, supporting both rule-based and cost-based optimization. When possible, Spark SQL Whole-Stage Java Code Generation optimizes CPU usage by generating a single optimized function in bytecode for the set of operators in an SQL query.
Exploring the Taxi Dataset with Spark SQL
Data preparation and exploration takes 60 to 80 percent of the analytical pipeline in a typical machine learning (ML) or deep learning (DL) project. In order to build an ML model, you have to clean, extract, explore, and test your dataset in order to find the features of interest that most contribute to the model’s accurate predictions. For illustrative purposes, we’ll use Spark SQL to explore the Taxi dataset to analyze which features might help predict taxi fare amounts.
Load the Data from a File into a DataFrame and Cache
The following code shows how we loaded the data from a CSV file into a Spark Dataframe, specifying the datasource and schema to load into a DataFrame, as discussed in Chapter 1. After we register the DataFrame as an SQL temporary view, we can use SQL functions on the SparkSession to run SQL queries, which will return the results as a DataFrame. We cache the DataFrame so that Spark does not have to reload it for each query. Also, Spark can cache DataFrames or Tables in columnar format in memory, which can improve memory usage and performance.

// load the data as in Chapter 1
val file = "/data/taxi_small.csv"
val df = spark.read.option("inferSchema", "false")
.option("header", true).schema(schema).csv(file)
// cache DataFrame in columnar format in memory
df.cache
// create Table view of DataFrame for Spark SQL
df.createOrReplaceTempView("taxi")
// cache taxi table in columnar format in memory
spark.catalog.cacheTable("taxi")
Using Spark SQL
Now we can use Spark SQL to explore what might affect the taxi fare amount, with questions like: What is the average fare amount by hour of the day?
%sql
select hour, avg(fare_amount)
from taxi
group by hour order by hour
With a notebook like Zeppelin or Jupyter, we can display the SQL results in graph formats.

Following is the same query with the DataFrame API:
df.groupBy("hour").avg("fare_amount")
.orderBy("hour").show(5)
result:
+----+------------------+
|hour| avg(fare_amount)|
+----+------------------+
| 0.0|11.083333333333334|
| 1.0|22.581632653061224|
| 2.0|11.370820668693009|
| 3.0|13.873989218328841|
| 4.0| 14.57204433497537|
+----+------------------+
What is the average fare amount compared to the average trip distance?
%sql
select trip_distance,avg(trip_distance), avg(fare_amount)
from taxi
group by trip_distance order by avg(trip_distance) desc

What is the average fare amount and average trip distance by hour of the day?
%sql
select hour, avg(fare_amount), avg(trip_distance)
from taxi
group by hour order by hour

What is the average fare amount and average trip distance by rate code?
%sql
select hour, avg(fare_amount), avg(trip_distance)
from taxi
group by rate_code order by rate_code

What is the average fare amount and average trip distance by day of the week?
%sql
select day_of_week, avg(fare_amount), avg(trip_distance)
from taxi
group by day_of_week order by day_of_week

Using Spark Web UI to Monitor Spark SQL
SQL Tab
You can use the Spark SQL tab to view Query execution information, such as the query plan details and SQL metrics. Clicking on the query link displays the DAG of the job.

Clicking on the +details in the DAG displays details for that stage

Clicking the Details link on the bottom displays the logical plans and the physical plan in text format.
In the query plan details, you can see:
- The amount of time for each stage.
- If partition filters, projection, and filter pushdown are occurring.
- Shuffles between stages (Exchange) and the amount of data shuffled. If joins or aggregations are shuffling a lot of data, consider bucketing.
- You can set the number of partitions to use when shuffling with the spark.sql.shuffle.partitions option.
- The join algorithm being used. Broadcast join should be used when one table is small and sort-merge join should be used for large tables. You can use broadcast hint to guide Spark to broadcast a table in a join. For faster joins with large tables using the sort-merge join algorithm, you can use bucketing to pre-sort and group tables. This will avoid shuffling in the sort merge.
Use the Spark SQL ANALYZE TABLE tablename COMPUTE STATISTICS to take advantage of cost-based optimization in the Catalyst Planner.
Jobs Tab
The Jobs tab summary page shows high-level job information, such as the status, duration, and progress of all jobs and the overall event timeline. Here are some metrics to check:
- Duration: Check the amount of time for the job.
- Stages succeeded/total tasks, succeeded/total: Check if there was stage/task failure.
Stages Tab
The stage tab displays summary metrics for all tasks. You can use the metrics to identify problems with an executor or task distribution. Here are some things to look for:
- Duration: Are there tasks that are taking longer? If your task process time is not balanced, resources could be wasted.
- Status: Are there failed tasks?
- Read Size, Write Size: is there skew in data size?
- If your partitions/tasks are not balanced, then consider repartitioning.
Storage Tab
The Storage tab displays DataFrames that are cached or persisted to disk with size in memory and size on disk information. You can use the storage tab to see if cached DataFrames are fitting into memory. If a DataFrame will be reused, and if it fits into memory, caching it will make execution faster.
Executors Tab
The Executors tab displays summary memory, disk, and task usage information by the executors that were created for the application. You can use this tab to confirm that your application has the amount of resources needed, using the following:
- Shuffle Read Write Columns: Shows size of data transferred between stages.
- Storage Memory Column: Features the current used/available memory.
- Task Time Column: Displays task time/garbage collection time.
Partitioning and Bucketing
File partitioning and Bucketing are common optimization techniques in Spark SQL. They can be helpful for reducing data skew and data shuffling by pre-aggregating data in files or directories. DataFrames can be sorted, partitioned, and/or bucketed when saved as persistent tables. Partitioning optimizes reads by storing files in a hierarchy of directories based on the given columns. For example, when we partition a DataFrame by year:
df.write.format("parquet")
.partitionBy("year")
.option("path", "/data ")
.saveAsTable("taxi")
The directory would have the following structure:
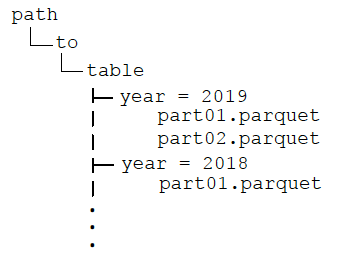
After partitioning the data, when queries are made with filter operators on the partition column, the Spark SQL catalyst optimizer pushes down the partition filter to the datasource. The scan reads only the directories that match the partition filters, reducing disk I/O and data loaded into memory. For example, the following query reads only the files in the year = '2019' directory.
df.filter("year = '2019')
.groupBy("year").avg("fareamount")
When visualizing the physical plan for this query, you will see Scan PrunedInMemoryFileIndex[ /data/year=2019], PartitionFilters: [ (year = 2019)] .
Similar to partitioning, bucketing splits data by a value. However, bucketing distributes data across a fixed number of buckets by a hash on the bucket value, whereas partitioning creates a directory for each partition column value. Tables can be bucketed on more than one value and bucketing can be used with or without partitioning. If we add bucketing to the previous example, the directory structure is the same as before, with data files in the year directories grouped across four buckets by hour.
df.write.format("parquet")
.partitionBy("year")
.bucketBy(4,"hour")
.option("path", "/data ")
.saveAsTable("taxi")
After bucketing the data, aggregations and joins (wide transformations) on the bucketed value do not have to shuffle data between partitions, reducing network and disk I/O. Also, bucket filter pruning will be pushed to the datasource reducing disk I/O and data loaded into memory. The following query pushes down the partition filter on year to the datasource and avoids the shuffle to aggregate on hour.
df.filter("year = '2019')
.groupBy("hour")
.avg("hour")
Partitioning should only be used with columns used frequently in queries for filtering and that have a limited number of column values with enough corresponding data to distribute the files in the directories. Small files are less efficient with excessive parallelism and too few large files can hurt parallelism. Bucketing works well when the number of unique bucketing column values is large and the bucketing column is used often in queries.
Summary
In this chapter, we explored how to use tabular data with Spark SQL. These code examples can be reused as the foundation for processing data with Spark SQL. In another chapter, we use the same data with DataFrames for predicting taxi fares.