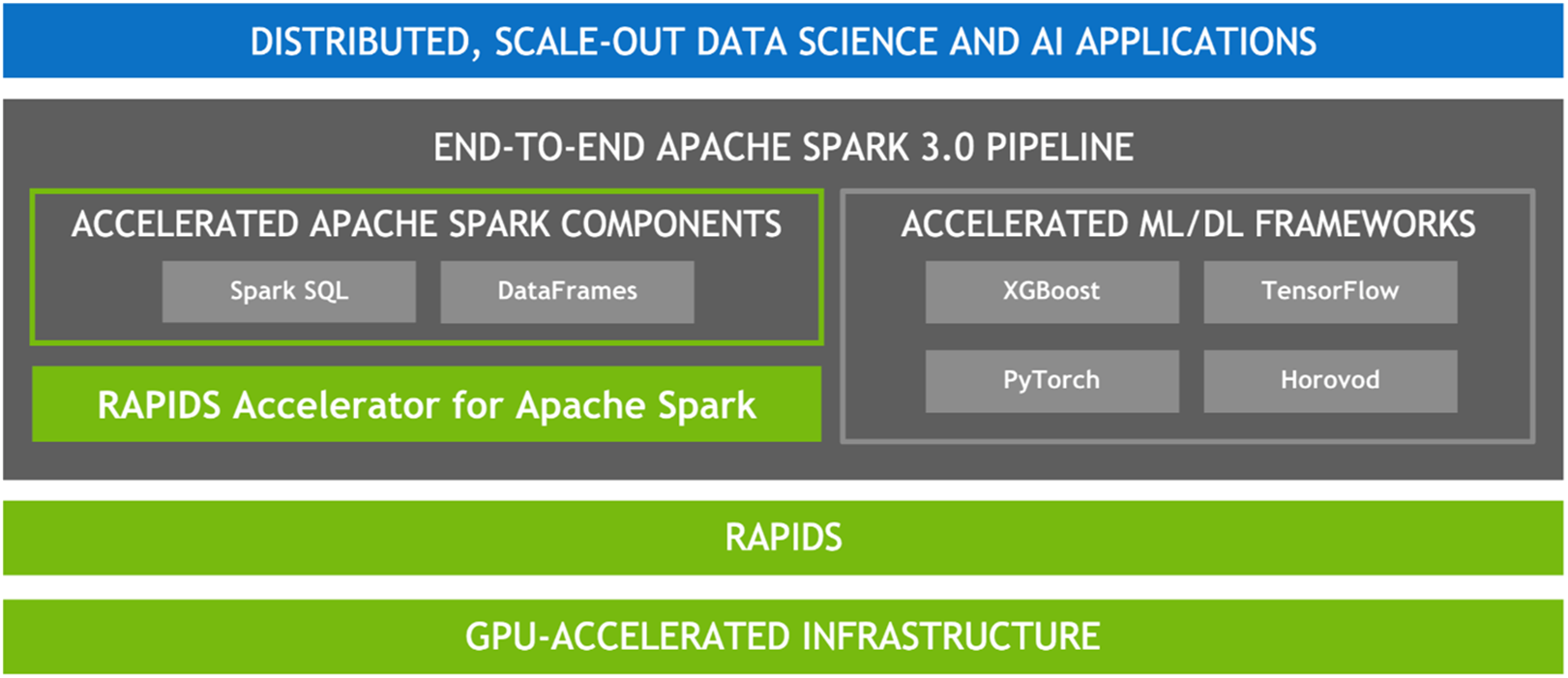
수많은 데이터 처리 작업의 병렬 성질을 감안하면, 당연히 GPU의 매우 병렬적인 아키텍처는 GPU가 인공지능(AI)에서 딥러닝(DL)을 가속화하는 것과 같은 방법으로 Spark 데이터 처리 쿼리를 병렬화 및 가속화해야 합니다. 따라서 NVIDIA® Spark 커뮤니티와 협력하여 Spark 3.x의 일부로 GPU 가속을 구현했습니다.
Spark는 파티션 형태로 노드 간에 컴퓨팅을 배포하지만 파티션 내에서는 전통적으로 CPU 코어에서 컴퓨팅이 수행되었습니다. 그러나 Spark에서 GPU 가속의 이점은 많습니다. 그 중 하나는, 서버가 더 적게 필요하여 인프라 비용이 절감된다는 것입니다. 쿼리가 더 빨리 완료되므로 결과 도출까지의 시간이 감소할 것으로 기대할 수 있습니다. 또한, GPU 가속이 투명하기 때문에 Spark에서 실행되도록 제작된 애플리케이션은 변경 없이도 GPU 가속의 이점을 얻을 수 있습니다.