Spark DataFrame은 클러스터의 여러 노드에 분할되어 병렬로 작동할 수 있는 org.apache.spark.sql.Row 개체의 분산된 데이터세트입니다. DataFrame은 R 또는 Python의 DataFrame과 유사하지만 Spark 최적화와 유사한 행 및 열이 있는 데이터 테이블을 나타냅니다. DataFrame은 파티션으로 구성되며, 각 파티션은 데이터 노드의 캐시에 있는 행 범위입니다.
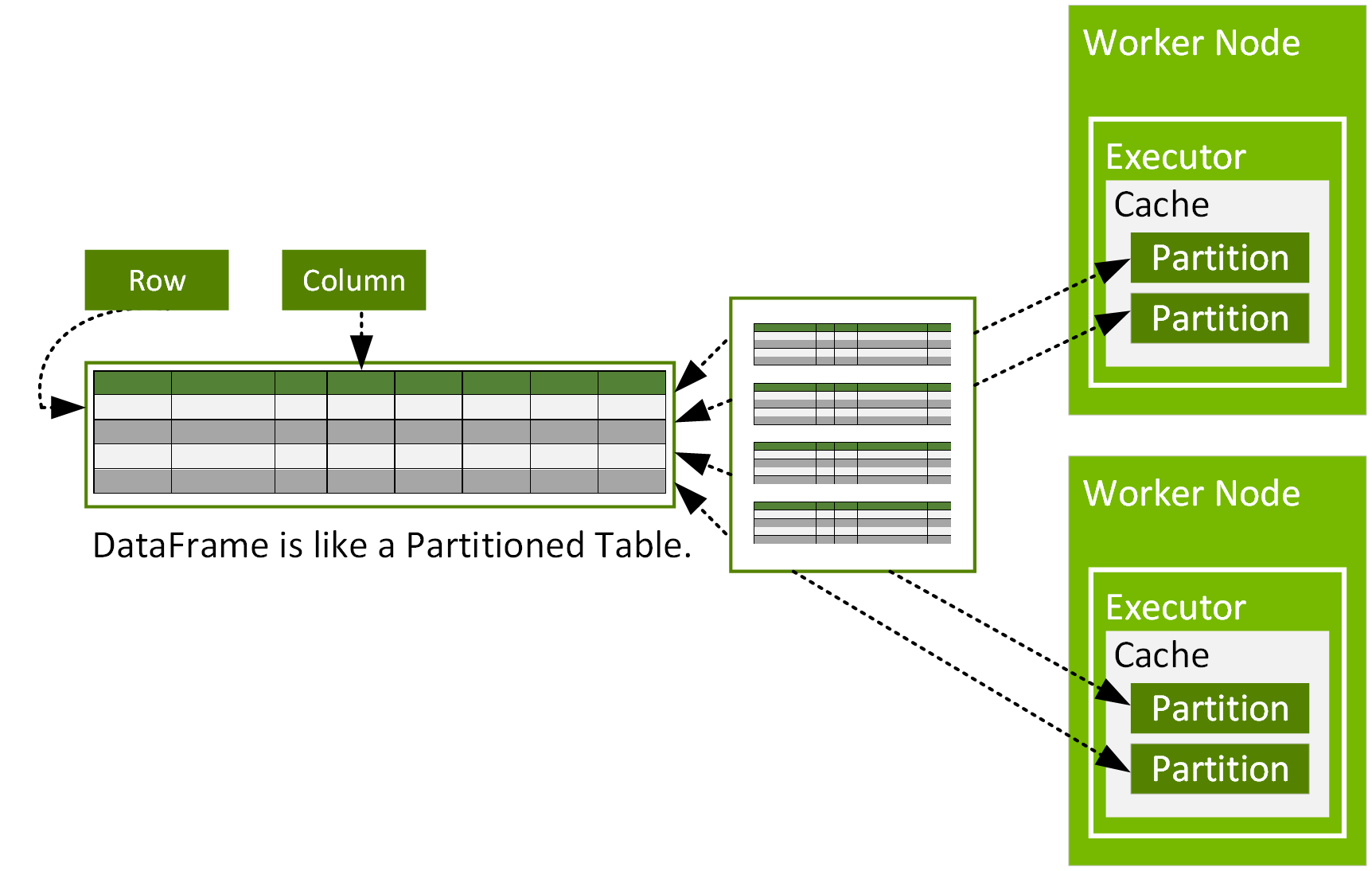
DataFrames는 csv, parquet, JSON 파일, Hive 테이블 또는 외부 데이터베이스와 같은 데이터 소스에서 구성할 수 있습니다. DataFrame은 관계형 변환 및 Spark SQL 쿼리를 사용하여 작동할 수 있습니다.
Spark 셸 또는 Spark 노트북은 Spark를 대화형으로 사용할 수 있는 간단한 방법을 제공합니다. 다음 명령으로 로컬 모드에서 셸을 시작할 수 있습니다.
$ /[installation path]/bin/spark-shell --master local[2]
그런 다음 이 챕터의 나머지 부분에 있는 코드를 셸에 입력하여 결과를 대화형으로 볼 수 있습니다. 코드 예제에서 셸의 출력은 결과가 맨 처음에 나옵니다.
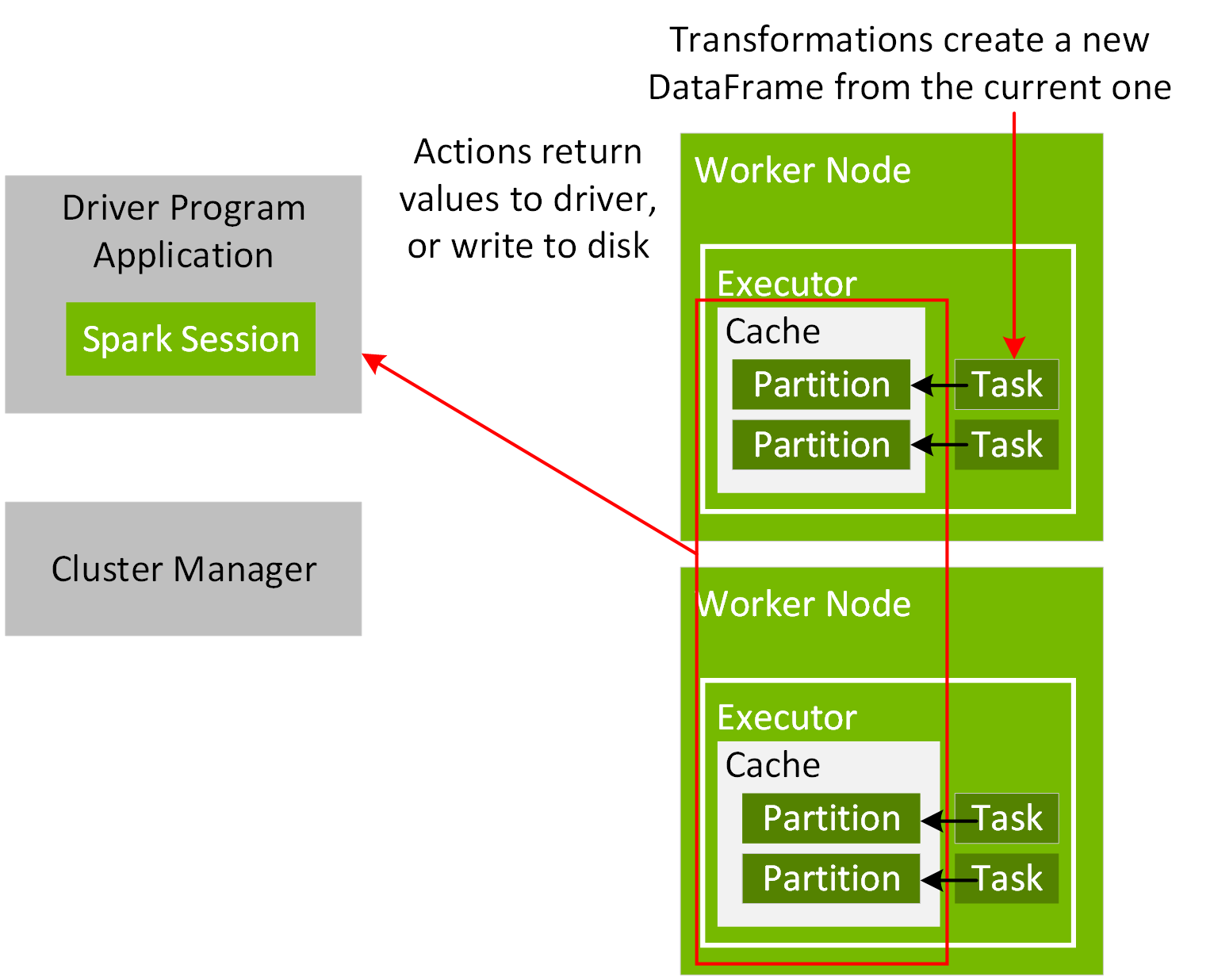
애플리케이션 드라이버와 클러스터 관리자 간의 실행 조정을 위해, 프로그램에서 다음 코드 예제와 같이 SparkSession 개체를 만듭니다.
val spark = SparkSession.builder.appName("Simple Application").master("local[2]").getOrCreate()
Spark 애플리케이션이 시작되면 마스터 URL을 통해 클러스터 관리자에게 연결됩니다. 마스터 URL은 SparkSession 개체를 만들거나 SparkSession 애플리케이션을 제출할 때 N 스레드를 사용하여 로컬로 실행되도록 클러스터 관리자 또는 로컬[N]으로 설정할 수 있습니다. Spark 셸 또는 노트북을 사용하는 경우 SparkSession 개체가 이미 만들어져 있으며 변수 Spark로 사용할 수 있습니다. 연결되면 클러스터 관리자는 클러스터의 노드에 대해 구성된 대로 리소스를 할당하고 실행자 프로세스를 시작합니다. Spark 애플리케이션이 실행되면 SparkSession은 실행을 위해 작업을 실행자에 보냅니다.
SparkSession 읽기 방법을 사용하면 파일에서 DataFrame으로 데이터를 읽고 스키마에 대한 파일 유형, 파일 경로 및 입력 옵션을 지정할 수 있습니다.
import org.apache.spark.sql.types._
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
val schema =
StructType(Array(
StructField("vendor_id", DoubleType),
StructField("passenger_count", DoubleType),
StructField("trip_distance", DoubleType),
StructField("pickup_longitude", DoubleType),
StructField("pickup_latitude", DoubleType),
StructField("rate_code", DoubleType),
StructField("store_and_fwd", DoubleType),
StructField("dropoff_longitude", DoubleType),
StructField("dropoff_latitude", DoubleType),
StructField("fare_amount", DoubleType),
StructField("hour", DoubleType),
StructField("year", IntegerType),
StructField("month", IntegerType),
StructField("day", DoubleType),
StructField("day_of_week", DoubleType),
StructField("is_weekend", DoubleType)
))
val file = "/data/taxi_small.csv"
val df = spark.read.option("inferSchema", "false")
.option("header", true).schema(schema).csv(file)
result:
df: org.apache.spark.sql.DataFrame = [vendor_id: double, passenger_count:
double ... 14 more fields]
take 메서드는 이 DataFrame의 개체가 포함된 배열을 반환하며, 이는 org.apache.spark.sql.Row 형식입니다.
df.take(1)
result:
Array[org.apache.spark.sql.Row] =
Array([4.52563162E8,5.0,2.72,-73.948132,40.829826999999995,-6.77418915E8,-1.0,-73.969648,40.797472000000006,11.5,10.0,2012,11,13.0,6.0,1.0])



