Uma Análise do Subsistema de Memória das GeForce RTX Série 40
Nós recebemos muitas perguntas sobre a memória das placas de vídeo, também conhecida como framebuffer, memória gráfica, memória de vídeo, ou simplesmente VRAM, e com o anúncio da nossa nova Família de placas de vídeo GeForce RTX 4060 achamos que seria uma boa oportunidade para compartilhar algumas considerações, para que os gamers possam fazer a melhor escolha de acordo com as suas necessidades.
O que é VRAM?
VRAM é uma memória de alta velocidade presente na placa de vídeo. É um dos componentes do subsistema de memória, que ajuda a garantir que a GPU tenha acesso aos dados necessários para processar e exibir imagens de forma fluida.
Nesse artigo vamos explorar as inovações no subsistema de memória da nossa arquitetura Ada Lovelace, e como o tamanho e a velocidade da memória cache e da VRAM impactam o desempenho da GPU e a experiência de jogo.
Subsistema de Memória das Placas de Vídeo GeForce RTX Série 40: Melhorando a Performance e a Eficiência
Jogos modernos são um espetáculo visual, e seus arquivos já superam os 100GB em muitos casos. O acesso a essa quantidade enorme de dados acontece em velocidades diferentes, dependendo da sua GPU e, até certo ponto, de outros componentes do seu sistema.
Nas placas de vídeo GeForce RTX Série 40 há uma série de inovações para acelerar esse processo e garantir uma jogatina fluida, com taxas de quadros mais altas, sem engasgos ou atrasos no carregamento de texturas.
A Importância do Cache
GPUs contam com memórias cache de alta velocidade, bem perto dos núcleos de processamento, que armazenam os dados que a GPU deve precisar em breve. Se a GPU pode acessar os dados do cache, em vez de requisitá-los à VRAM (que está mais “longe”) ou à RAM (a memória do sistema, que está mais “longe” ainda), os dados serão chegarão aos núcleos e serão processados em menos tempo, melhorando o desempenho, a fluidez da jogatina e reduzindo o consumo de energia.
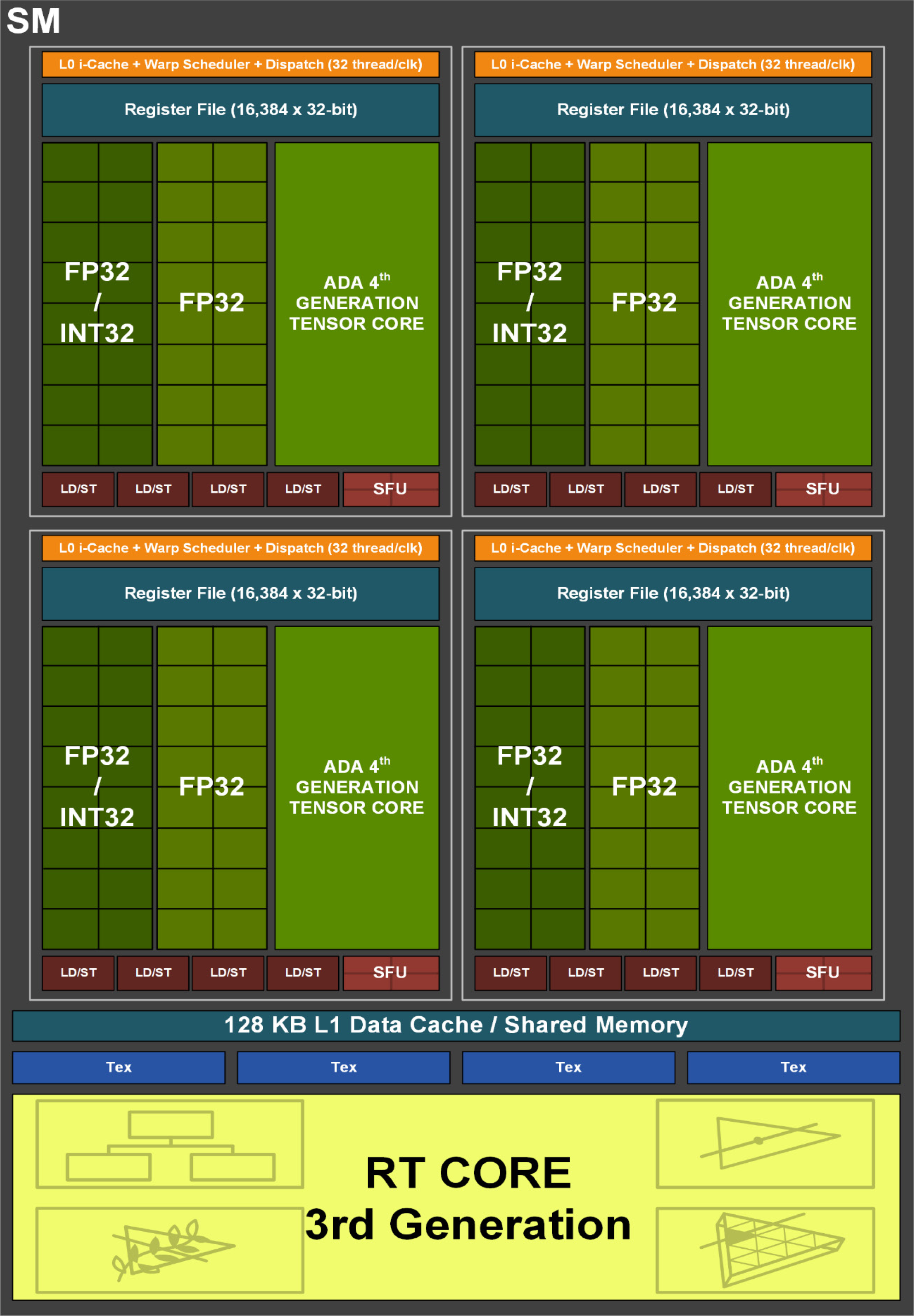
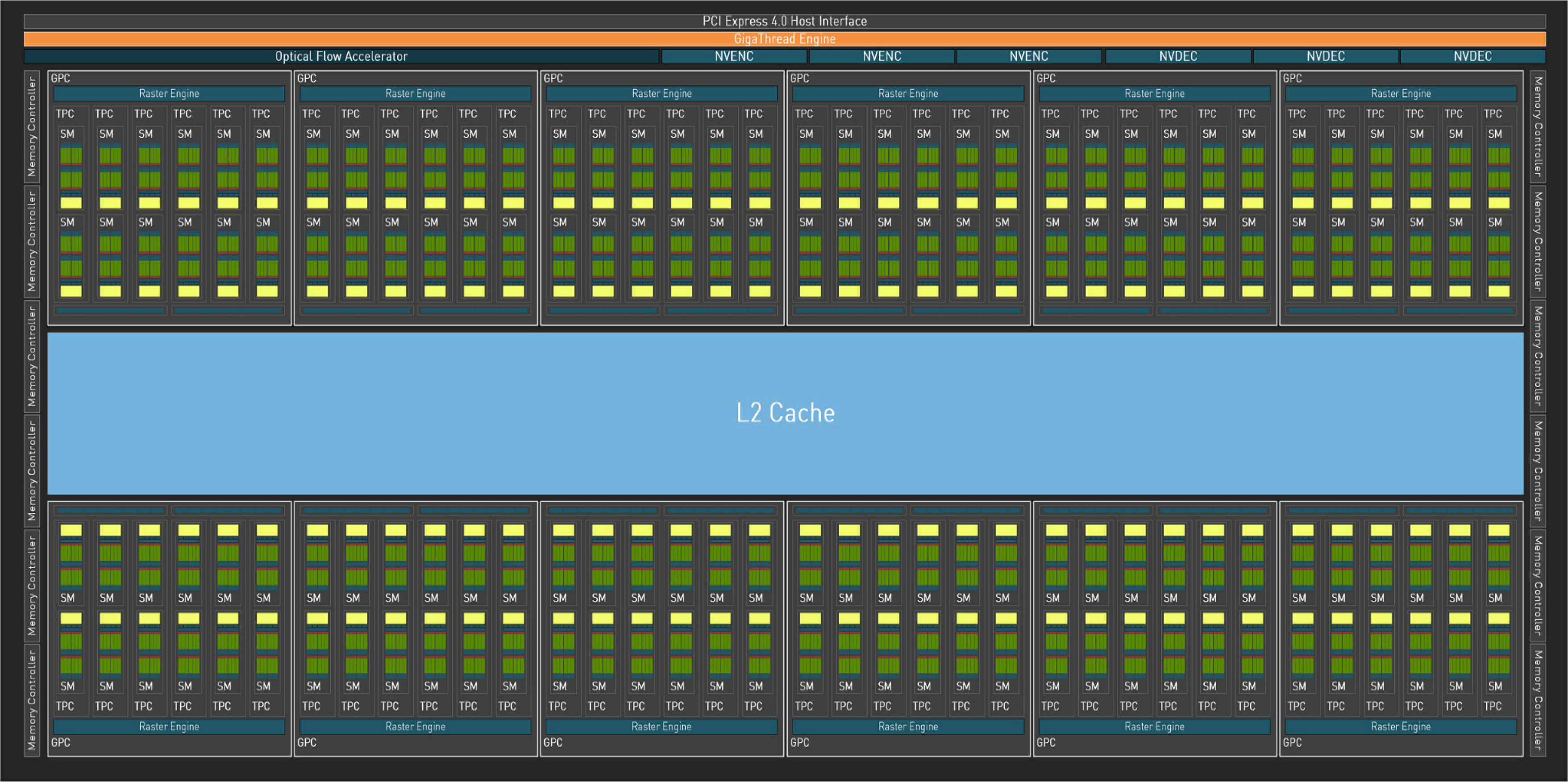
GPUs GeForce possuem um Cache L1 (Level 1, ou Nível 1) em cada SM (Streaming Multiprocessor, ou Multiprocessador de Dados, em uma tradução adaptada; que na Arquitetura Ada constitui um conjunto de 128 Núcleos CUDA), nas GeForce RTX Série 40 cada GPC (Graphics Processing Cluster) pode contar com até 12 SMs. Logo depois dos GPCs temos um Cache L2, ainda muito rápido, mas principalmente, muito maior que o L1; que pode ser acessado com altíssima velocidade e latência muito baixa.
O acesso a cada Nível superior de cache implica em uma latência mais alta; mas, em contrapartida, sua capacidade é muito maior. Durante o desenvolvimento das nossas GPUs GeForce RTX Série 40 concluímos que um cache L2 unificado e de grande capacidade é mais rápido e mais eficiente que outras opções, como usar um cache L2 pequeno e um cache L3 maior e mais lento.
Gerações anteriores de GPUs GeForce contavam com Caches L2 muito menores, resultando em menor performance e eficiência, quando comparadas às atuais GeForce RTX Série 40.

Durante o uso, a GPU primeiro procura pelos dados no Cache L1 localizado dentro do SM, se os dados forem encontrados ali, não é necessário acessar o Cache L2. Se os dados não forem encontrados no L1, isso é chamado um “erro de cache” (cache miss, erro no sentido de “errar o alvo”), a busca continua no Cache L2. Se os dados forem encontrados no L2, isso é chamado de um “acerto de cache” (cache hit) no L2 (observe os “H”s no diagrama acima), os dados serão enviados ao cache L1 e então aos núcleos de processamento.
Se os dados não forem encontrados no cache L2, um “erro de cache” no L2, a GPU então tentará obter os dados da VRAM. Observe o número de “erros” do L2 no diagrama acima, que mostra o subsistema de memória da nossa arquitetura anterior, que causa um maior número de acessos à VRAM.
Se os dados não estiverem na VRAM, a GPU os solicitará da memória do sistema. Se os dados não estiverem lá, deve ser carregado desde um dispositivo de armazenamento, como um SSD ou HD mecânico. Os dados são então copiados para a VRAM, Cache L2, Cache L1 e finalmente chegam aos núcleos de processamento (os famosos CUDA Cores). Lembrando que há diferentes estratégias de hardware e software para manter em cache os dados mais úteis e reutilizados.
Cada operação de memória, seja de leitura ou escrita, através dos distintos níveis dessa hierarquia, reduz a performance como um todo e usa mais energia, então se aumentarmos o “índice de acertos” (hit rate) dos caches, aumentamos também a taxa de quadros por segundo e a eficiência da placa.

Comparado a gerações anteriores com barramento de memória de 128 bits, o subsistema de memória da arquitetura NVIDIA Ada Lovelace aumentou o tamanho do cache L2 em 16 VEZES, aumentando enormemente o índice de acerto do cache. No exemplo acima, representando GPUs de 128 bits da arquitetura Ada e das gerações anteriores. Além disso, a largura de banda do cache L2 também aumentou bastante na arquitetura Ada, se comparada a gerações anteriores. Isso permite que mais dados sejam transferidos do cache L2 para os núcleos de processamento no menor tempo possível.
No diagrama abaixo, engenheiros da NVIDIA testaram a RTX 4060 Ti com seus 32MB de cache L2 contra uma versão especial para testes da RTX 4060 Ti com apenas 2MB de cache L2, que representa a capacidade de L2 disponível em gerações passadas de placas com barramento de 128 bits (onde havia uma fatia de 512KB de cache L2 associada a cada controlador de memória de 32 bits).
Ao testar uma variedade de jogos e benchmarks sintéticos, o cache L2 de 32MB reduziu o tráfego de dados no barramento de memória em uma média de pouco mais de 50%, se comparado ao desempenho do cache L2 de 2MB. O diagrama anterior (acima) mostra a redução de acessos a VRAM no subsistema de memória da arquitetura Ada.
Essa redução de 50% no tráfego de dados permite que a GPU use sua largura de banda de memória com 2x mais eficiência. O resultado, nesse cenário isolado à performance da memória, é que uma GPU Ada com uma banda de memória de 288GB/s teria um desempenho semelhante a uma GPU Ampere (RTX Série 30) com banda de memória de 554GB/s. Em uma variedade de jogos e benchmarks sintéticos, esse grande aumento na taxa de acertos do cache melhora a taxa de quadros por segundo em até 34%

A Largura do Barramento é Apenas Um dos Vários Aspectos de um Subsistema de Memória
Historicamente, a largura do barramento de memória é uma métrica importante para determinar o desempenho e a classe de performance de uma GPU. Porém, apenas o barramento não é suficiente para indicar o desempenho de um subsistema de memória. É melhor entender o projeto do subsistema de memória como um todo e seu impacto no desempenho em jogos.
Graças aos avanços da arquitetura Ada, incluindo novos RT e Tensor Cores, clocks mais altos, o novo OFA (Optical Flow Accelerator) e recursos como o DLSS 3; a GeForce RTX 4060 Ti é mais rápida que placas de 256 bits de gerações passadas, como a GeForce RTX 3060 Ti e a RTX 2060 SUPER, e faz isso usando menos energia.
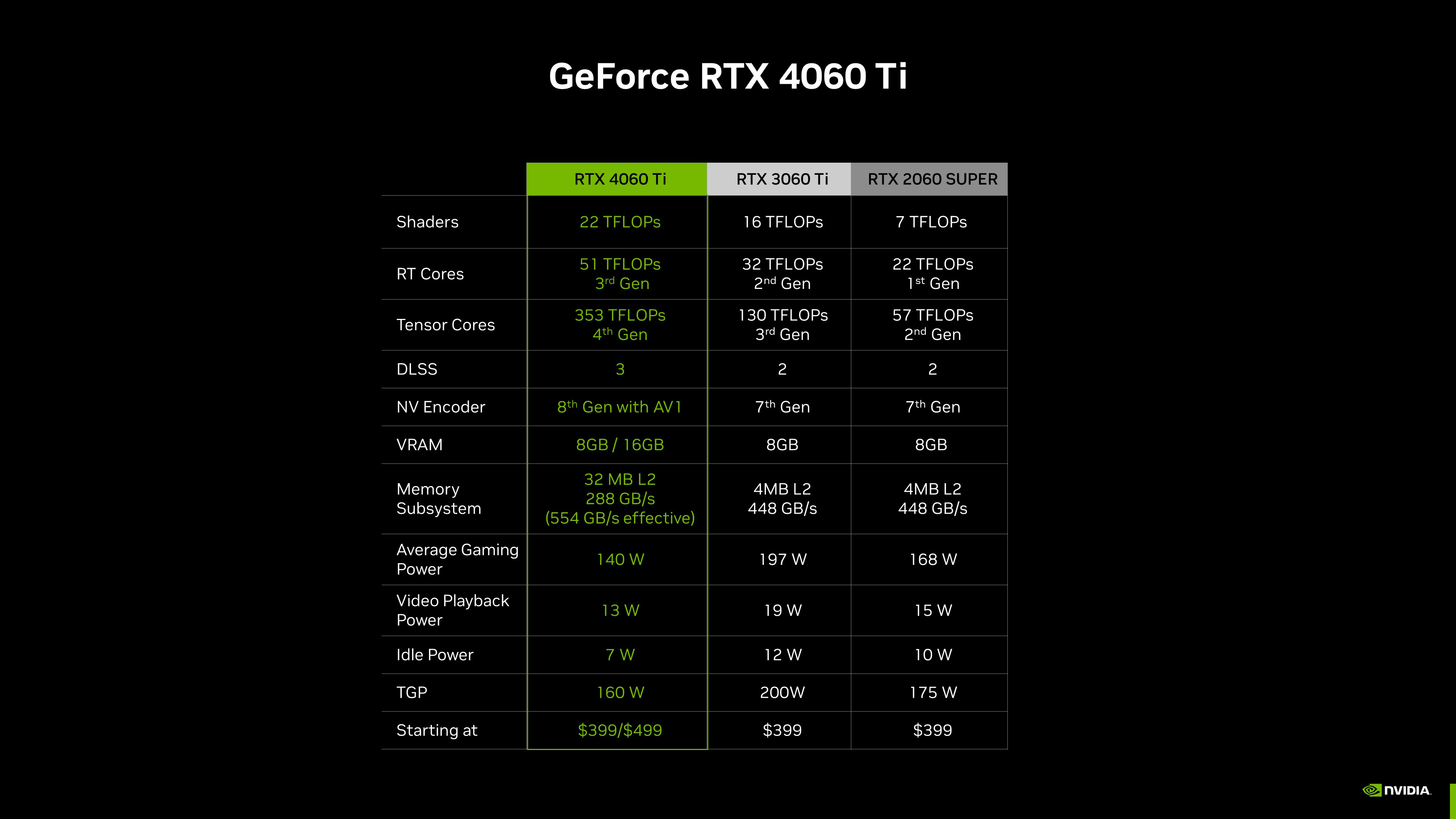
Resumindo, essas especificações entregam uma ótima GPU da “Classe-60” com alto desempenho para 1080p, o que representa a maioria dos usuários segundo o Steam.

A Quantidade de VRAM Depende da Arquitetura da GPU
Os jogadores às vezes se perguntam por que uma placa de vídeo tem uma determinada quantidade de VRAM.
As memórias atuais GDDR6X e GDDR6 estão disponíveis com densidade de 8Gb (ou 1GB de dados) e 16Gb (2GB) por chip. Cada chip usa dois canais de 16 bits para se conectar a um controlador de memória de 32 bits; ou dois canais de 8 bits, assim dois chips podem se conectar a um único controlador de memória de 32 bits na Arquitetura Ada. Assim uma GPU com barramento de 128 bits suporta 4 ou 8 chips de memória.
Chips de maior capacidade, obviamente, são mais caros, então é necessário balancear as configurações para otimizar custos.
Na GeForce RTX 4060 Ti, o modelo de 8GB usa quatro chips GDDR6 de 16Gb (2GB), enquanto o modelo de 16GB usa oito chips, também de 16Gb (2GB) cada. Não é possível misturar chips de densidades diferentes, o que impede a criação de um modelo de 12GB, por exemplo. Por isso também que a GeForce RTX 4060 Ti pode ter uma versão com mais memória (16GB) que as GeForce RTX 4070 Ti e 4070, que possuem barramentos de 192 bits e, portanto, 12GB de memória.
Nossas GPUs da Classe-60 foram cuidadosamente criadas para oferecer uma combinação ótima de desempenho, preço e eficiência energética, por isso que escolhemos um barramento de 128 bits.
Resumindo, para oferecer mais memória em uma GPU sem alterar o barramento de memória é necessário dobrar a quantidade de chips de memória.
Ferramentas de Monitoramento Exibem o uso Correto de VRAM?
Jogadores costumam citar o “uso de VRAM” exibido no overlay (OSD) de ferramentas para monitoramento de performance. Mas esse número nem sempre é preciso, já que distintos engines de jogos trabalham de forma diferente.
Na maioria dos casos, um jogo irá alocar VRAM “dizendo” ao sistema, “não sei se vou precisar de tudo, mas quero tanta memória”. Mas o jogo não necessariamente precisa de toda a memória alocada. De fato, muitos jogos simplesmente pedem toda a memória que houver disponível.
Dependendo de como o jogo funciona, é basicamente impossível saber exatamente quais dados estão ativamente em uso, a menos que você tenha acesso às ferramentas de desenvolvimento do jogo. Alguns jogos oferecem, em seus menus de configuração, informações sobre a quantidade de memória necessária, mas mesmo essas nem sempre são precisas.
A quantidade de VRAM que é realmente necessária também varia em tempo real, dependendo da cena que o jogador vê.
Além disso, o comportamento dos jogos ao utilizar a VRAM no limite também varia bastante. Em alguns, quando parte da memória é descarregada, ocorre um sensível impacto no desempenho (as populares travadinhas) enquanto novos dados são carregados. Em outros, apenas alguns dados são carregados e descarregados, sem nenhum impacto visual. E em alguns casos, novos objetos podem demorar mais para aparecer enquanto são carregados da RAM (memória do sistema).
Para os jogadores, jogar é a única forma de descobrir o verdadeiro comportamento de um jogo. Além disso, podem-se observar estatísticas como a taxa de quadros “1% low”, para ajudar a determinar qual será a real experiência de jogo. A métrica de 1% Low – encontrada em displays e logs de ferramentas para análise de desempenho, como o gratuito NVIDIA FrameView e outros programas famosos – mede a média entre os 1% frames mais baixos ao longo de um determinado período de tempo.
Otimize os Ajustes Automaticamente com GeForce Experience e Instale as Últimas Atualizações
Recentemente alguns jogos lançaram atualizações para melhorar o gerenciamento de memória sem prejudicar a qualidade da imagem. Certifique-se de que seus jogos estejam completamente atualizados, uma vez que é comum que correções para bugs e problemas de performance sejam lançados pouco após o lançamento.
Além disso, o GeForce Experience suporta a maioria dos jogos recém lançados, oferecendo configurações otimizadas para cada GPU GeForce, levando em conta sua capacidade de memória, entregando aos jogadores a melhor experiência possível, balanceado desempenho e qualidade de imagem.
Se você não está familiarizado com as opções gráficas dos jogos e apenas quer se divertir, o GeForce Experience pode otimizá-los automaticamente, para que você sempre tenha a melhor experiência.
Tecnologias NVIDIA Que Podem Ajudar Os Desenvolvedores a Reduzir o Uso de VRAM
Os jogos são mais ricos e detalhados que nunca, exigindo aqueles 100GB ou mais para sua instalação. Para ajudar os desenvolvedores a otimizar o uso de memória, a NVIDIA oferece uma série de ferramentas e SDKs gratuitos, incluindo:
- NVIDIA RTX Memory Utility (RTXMU): Ray Tracing exige mais memória. O RTXMU pode ajudar a reduzir esse aumento em até 50%
- NVIDIA Micro-Mesh SDK: Reduz o uso de memória por objetos de geometria complexa, ao mesmo tempo que melhora o desempenho
- NVIDIA Texture Tools Exporter: Cria arquivos de texturas altamente comprimidos para reduzir o uso de memória e o espaço necessário para a instalação dos jogos
Estas são apenas algumas das ferramentas e tecnologias que a NVIDIA oferece gratuitamente para ajudar os desenvolvedores a otimizar seus jogos para todas as GPUs, plataformas e configurações de memória.
Algumas Aplicações Podem Usar Mais VRAM
Além dos jogos, as placas de vídeo GeForce RTX são usadas em todo o mundo para criar animações 3D, editar vídeos, fotografias, design gráfico, visualização de arquitetura, STEM, broadscasting (transmissões ao vivo por stream ou para TV) e para Inteligência Artificial. Algumas aplicações usadas nessas indústrias podem se beneficiar de mais VRAM. Por exemplo, ao editar vídeos 4K ou 8K no Premiere, ou criando obras massivas de arquitetura no D5 Render.
De volta aos jogos, altas resoluções normalmente requerem mais VRAM. Alguns jogos trazem um pacote opcional com texturas de altíssima resolução e alocam mais memória. E tem alguns jogos que rodam melhor em configuração “Alta” na 4060 Ti (8GB) e com tudo no máximo na 4060Ti (16GB). Na maioria dos jogos, ambas versões da GeForce RTX 4060 Ti (8GB e 16GB) podem rodar com todos os detalhes no máximo e entregam a mesma performance.
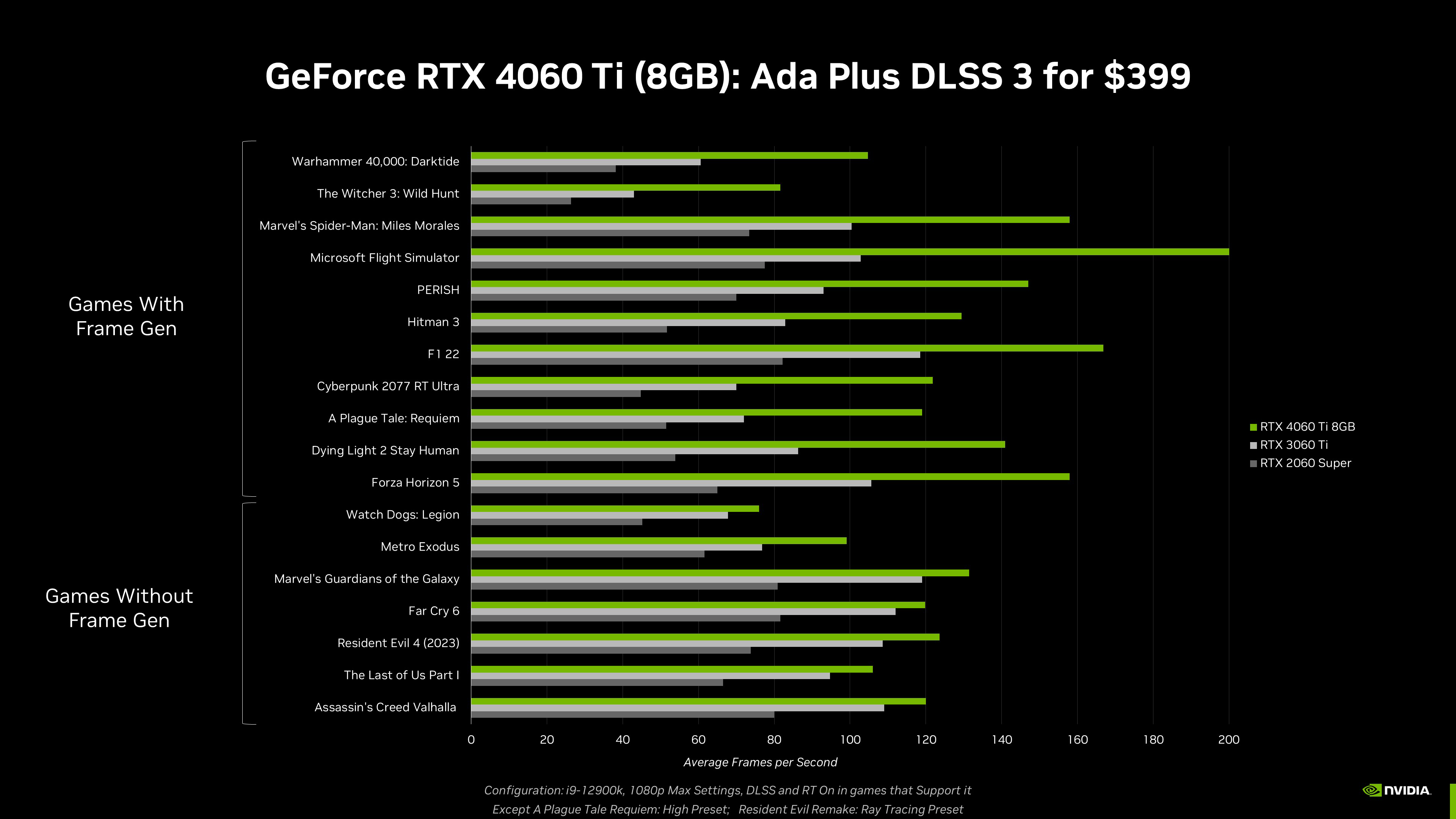
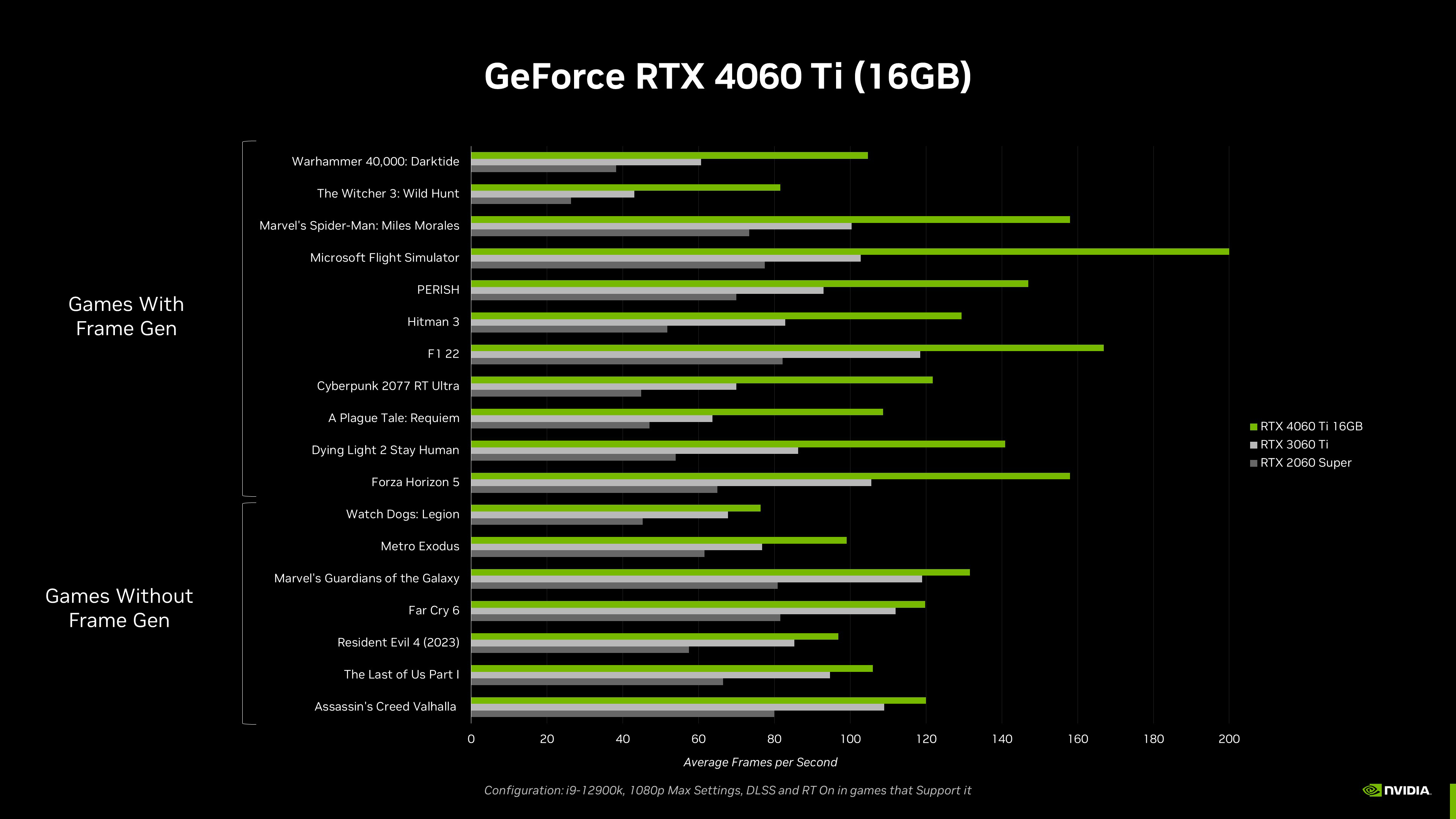
A maior vantagem da plataforma PC é que é aberta, permite diversas configurações e ainda dá espaço para upgrades, por isso vamos oferecer duas configurações de memória para a GeForce RTX 4060 Ti; se você preferir a versão com mais memória, ela estará disponível em Julho.
Uma GPU Para Cada Gamer
Com o lançamento da Família GeForce RTX 4060, haverá placas de vídeo otimizadas para cada uma das 3 principais resoluções usadas pelos gamers. Não importa como você jogue, todas as GPUs GeForce RTX Série 40 oferecerão a melhor experiência da categoria, com a melhor eficiência energética e suporte a uma longa lista de tecnologias feitas para melhorar o seu game, como NVIDIA DLSS 3, NVIDIA Reflex, NVIDIA G-SYNC, NVIDIA Broadcast, e RTX Remix.

Para saber de todas as novidades em jogos e aplicações que aproveitam as capacidades das placas de vídeo GeForce RTX, fique ligado no GeForce.com e em nossas redes sociais @nvidiageforcebr