在第 1 章,我們探討了 Spark DataFrame 如何在叢集中執行。在本章節,我們會介紹 DataFrame 和 Spark SQL 程式設計概覽與其優勢。
Spark SQL 和 DataFrame 程式設計
DataFrame 和 Spark SQL 優勢
搭載 Spark SQL 最佳化執行引擎的 Spark SQL 和 DataFrame API 不僅易於使用,還能增加空間效率並提升效能。
記憶體使用最佳化
Spark SQL 使用記憶體內欄式格式快取 DataFrame (當您呼叫 dataFrame.cache 時),該格式已經最佳化以:僅掃描所需欄位、自動調整壓縮、將記憶體使用量降至最低並盡可能減少 JVM 垃圾回收 (Garbage Collection)。

Spark SQL 向量化 Parquet 和 ORC 讀取器以欄位批次進行解壓縮和解碼,讓讀取速度約提升了九倍。
查詢最佳化
Spark SQL 的 Catalyst 最佳化工具可處理邏輯最佳化和實體計畫,支援規則型和成本型的最佳化。在適用的情況下,Spark SQL 全階段 Java 程式碼產生 (Code Generation) 會為 SQL 查詢中的運算子集產生最佳化單一函數的位元組程式碼,以最佳化 CPU 使用率。
使用 Spark SQL 探索計程車資料集
在典型的機器學習 (ML) 或深度學習 (DL) 專案中,資料準備和探索會占用 60% 到 80% 的分析管線。為了建構機器學習模型,您必須清理、提取、探索和測試資料集,以找到對模型準確預測最有幫助的有利特徵。為了說明,我們將使用 Spark SQL 探索計程車資料集,分析哪些特徵可能有助於預測計程車車資。
將檔案的資料載入 DataFrame 和快取
下列程式碼說明我們如何如第 1 章所述,指定要載入至 DataFrame 的資料來源和架構,將 CSV 檔中的資料載入 Spark Dataframe。我們將 DataFrame 註冊為 SQL 臨時檢視後,可以使用 SparkSession 上的 SQL 功能來執行 SQL 查詢,並以 DataFrame 呈現結果。我們快取 DataFrame,Spark 便無須在每次查詢時重新載入。此外,Spark 還可以在記憶體內快取以欄式格式呈現的 DataFrame 或表格,可改善記憶體使用狀況和效能。

// 載入第 1 章的資料
val file ="/data/taxi_small.csv"
val df =spark.read.option("inferSchema", "false")
.option("header", true).schema(schema).csv(file)
// 快取記憶體內以欄式格式呈現的 DataFrame
df.cache
// 建立 Spark SQL DataFrame 的表格檢視
df.createOrReplaceTempView("taxi")
// 快取記憶體內以欄式格式呈現的計程車表格
spark.catalog.cacheTable("taxi")
使用 Spark SQL
我們現在可以使用 Spark SQL 探索可能影響計程車車資的因素並探討問題,像是:一天每小時的平均車資是多少?
%sql
select hour, avg(fare_amount)
from taxi
group by hour order by hour
我們可使用 Zeppelin 或 Jupyter 這類的筆記本,以圖形格式顯示 SQL 結果。

以下是透過 DataFrame API 進行相同的查詢:
df.groupBy("hour").avg("fare_amount")
.orderBy("hour").show(5)
result:
+----+------------------+
|hour| avg(fare_amount)|
+----+------------------+
| 0.0|11.083333333333334|
| 1.0|22.581632653061224|
| 2.0|11.370820668693009|
| 3.0|13.873989218328841|
| 4.0| 14.57204433497537|
+----+------------------+
與平均行程距離相比,平均車資是多少?
%sql
select trip_distance,avg(trip_distance), avg(fare_amount)
from taxi
group by trip_distance order by avg(trip_distance) desc

一天每小時的平均車資和平均行程距離是多少?
%sql
select hour, avg(fare_amount), avg(trip_distance)
from taxi
group by hour order by hour

依費率代碼計算的平均車資和平均行程距離是多少?
%sql
select hour, avg(fare_amount), avg(trip_distance)
from taxi
group by rate_code order by rate_code

一週每天的平均車資和平均行程距離是多少?
%sql
select day_of_week, avg(fare_amount), avg(trip_distance)
from taxi
group by day_of_week order by day_of_week

使用 Spark Web UI 監控 Spark SQL
SQL 分頁
您可以使用 Spark SQL 分頁檢視查詢執行資訊,例如查詢計畫的詳細資訊和 SQL 指標。按一下查詢連結以顯示作業的 DAG。

按一下 DAG 中的「+details」可顯示該階段的詳細資訊

按一下底部的詳細資訊連結,以文字格式顯示邏輯計畫和實體計畫。
您可以在查詢計畫詳細資訊看到下列項目:
- 每個階段的時間長度。
- 是否有發生分割區篩選、預測和篩選下推。
- 在階段間 (Exchange) 的隨機置換和隨機置換的資料量。如果聯結 (join) 或彙總 (aggregations) 隨機置換大量資料,請考慮使用分組 (bucketing)。
- 使用 spark.sql.shuffle.partitions 選項隨機置換時,可以設定要使用的分割區數量。
- 使用到的聯結演算法。小型表格應使用廣播聯結,而大型表格則應使用排序合併聯結 (sort-merge join)。您可以使用廣播提示 (broadcast hint) 引導 Spark 在聯結中廣播表格。若要透過排序合併聯結演算法快速與大型表格聯結,可以使用分組以預先排序並分組表格。如此便可避免在排序合併中進行隨機置換。
使用表格名稱為 COMPUTE STATISTICS 的 Spark SQL ANALYZE TABLE,以利用 Catalyst 規劃工具中的成本型最佳化功能。
作業分頁
作業分頁摘要頁面顯示高級作業資訊,例如所有作業的狀態、持續時間、進度以及整體事件的時程表。以下是要檢查的部分指標:
- 持續時間:檢查作業時間。
- 成功的階段/工作總數,已成功/總數:檢查是否有階段/工作失敗。
階段分頁
階段分頁顯示所有工作的摘要指標。您可以使用這些指標來識別執行程式或工作分配的問題。以下是需要尋找的一些項目:
- 持續時間:是否有工作需要花更長的時間? 如果您的工作處理時間不平衡,可能會浪費資源。
- 狀態:是否有失敗的工作?
- 讀取大小、寫入大小:資料大小是否有扭曲 (skew)?
- 如果您的分割區/工作不平衡,請考慮重新分割。
儲存分頁
「儲存」分頁顯示快取或保留至磁碟上的 DataFrame,以及記憶體內大小和磁碟上大小的資訊。您可以使用儲存標籤查看快取的 DataFrame 大小是否適合記憶體。如果 DataFrame 會重新利用,且其大小適合記憶體,則將其快取能夠加快執行速度。
執行程式分頁
執行程式分頁顯示為應用程式建立的執行者程式的摘要記憶體、磁碟和工作使用資訊。您可以使用以下分頁確認應用程式具有所需的資源量:
- 隨機置換讀寫欄:顯示階段之間傳輸的資料大小。
- 儲存記憶體欄:提供目前已使用/可用記憶體。
- 工作時間欄:顯示工作時間/垃圾回收時間。
分割和分組
檔案分割和分組是 Spark SQL 中常見的最佳化技術。這些技術可預先彙總檔案或目錄中的資料,協助減少資料扭曲和資料隨機置換。DataFrame 可在儲存為永久性表格時排序、分割和/或分組。分割依照指定欄將檔案儲存在目錄階層中,以將讀取最佳化。例如,當我們依照年份分割 DataFrame:
df.write.format("parquet")
.partitionBy("year")
.option("path", "/data ")
.saveAsTable("taxi")
目錄會有以下結構:
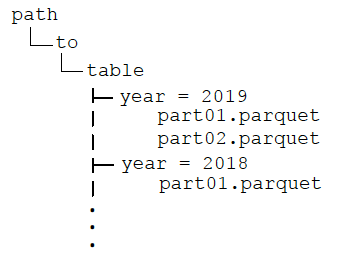
After partitioning the data, when queries are made with filter operators on the partition column, the Spark SQL catalyst optimizer pushes down the partition filter to the datasource. The scan reads only the directories that match the partition filters, reducing disk I/O and data loaded into memory. For example, the following query reads only the files in the year ='2019' directory.
df.filter("year ='2019')
.groupBy("year").avg("fareamount")
When visualizing the physical plan for this query, you will see Scan PrunedInMemoryFileIndex[ /data/year=2019], PartitionFilters: [ (year =2019)] .
與分割相似,分組按照值來分隔資料。但是,分組會依照分組值上的雜湊值在固定數量的分組間分配資料,分割則是為每個分割欄值建立目錄。表格可以根據多個值來分組,而且可以選擇是否要分割。如果我們將分組加入上一個範例,目錄結構與之前的相同,年目錄中的資料檔案依照小時分為四組。
df.write.format("parquet")
.partitionBy("year")
.bucketBy(4,"hour")
.option("path", "/data ")
.saveAsTable("taxi")
將資料分組後,分組值上的彙總和聯結 (廣泛轉換) 不須在分割區之間隨機置換資料,所以也不會因而減少網路和磁碟 I/O。此外,分組篩選條件剪除 (pruning) 會推至資料來源,可減少磁碟 I/O 和載入到記憶體內的資料。下方的查詢將年份的分割篩選器下推至資料來源,避免以小時彙總的隨機置換。
df.filter("year ='2019')
.groupBy("hour")
.avg("hour")
分割僅應使用在經常用於篩選查詢的欄,且這些欄的欄值有限,具有足夠的對應資料來分配目錄中的檔案。小型檔案效率低,平行處理過於龐大,而大型檔案過少則會對平行處理有不良影響。當唯一的分組欄值數量很多,而且分組欄經常用於查詢時,分組的效果良好。
摘要
在本章節中,我們將探討如何透過 Spark SQL 使用表格式資料。在使用 Spark SQL 處理資料時,這些程式碼範例可以做為基礎重複使用。在另一章節,我們會使用 DataFrames 相同資料來預測計程車車資。